Welcome back to the Building an Event Management System with Claude Code series! In Part 7, we built the foundation of our Import MCP Server, implemented two crucial core functions (validate_import_data and preview_import), and successfully connected Claude Desktop to our custom MCP server. We also encountered and fixed (temporarily) a connection issue that we documented as a GitHub issue for a proper fix later.
- To see all posts in the series, go to: Building an Event Management System with Claude Code.
Today, we’re implementing the real meat of the Import MCP Server: the import functions that will transform our manual CSV-wrangling nightmare into a 5-minute conversation. Along the way, we’ll discover how Claude Code excels not just at writing code, but at reviewing code, diagnosing performance issues, and proposing architectural solutions, skills that make it an invaluable development partner.
What We’re Building Today
By the end of this post, we’ll have implemented:
- ✅
import_quicket_registrations()- Foundation data: contacts + tickets - ✅
import_quicket_checkins()- Attendance tracking updates - ✅
import_checkin_walkins()- Walk-in attendee handling - ✅
import_sessionize_speakers()- Speaker and session management - ✅
import_speaker_ratings()- Session evaluations with fuzzy matching
NOTE: My track record of covering what I say we’ll cover is not the best, so if we don’t get to all five today, don’t be surprised if we pick up the remaining ones in the next post.
More importantly, we’ll transform what used to take 2-3 hours of manual Excel work into a conversational workflow that takes less than 10 minutes.
The Architecture: A Quick Reminder
Before we dive into implementation, let’s revisit a critical architectural decision from Parts 6 and 7 that shapes everything we build today.
The MCP Server Isolation Constraint
In Part 6 and Part 7, we discovered a fundamental constraint of the MCP protocol:
MCP servers CANNOT communicate with each other directly.
They’re isolated processes that communicate only through the MCP host (in this case, Claude Desktop/Code). This means our Import MCP Server cannot call tools from Postgres MCP Pro, even though both servers are running and connected to the host.
This led to our architectural decision: the Import MCP Server is self-contained. It has its own direct database connection and handles all data transformations and writes internally:
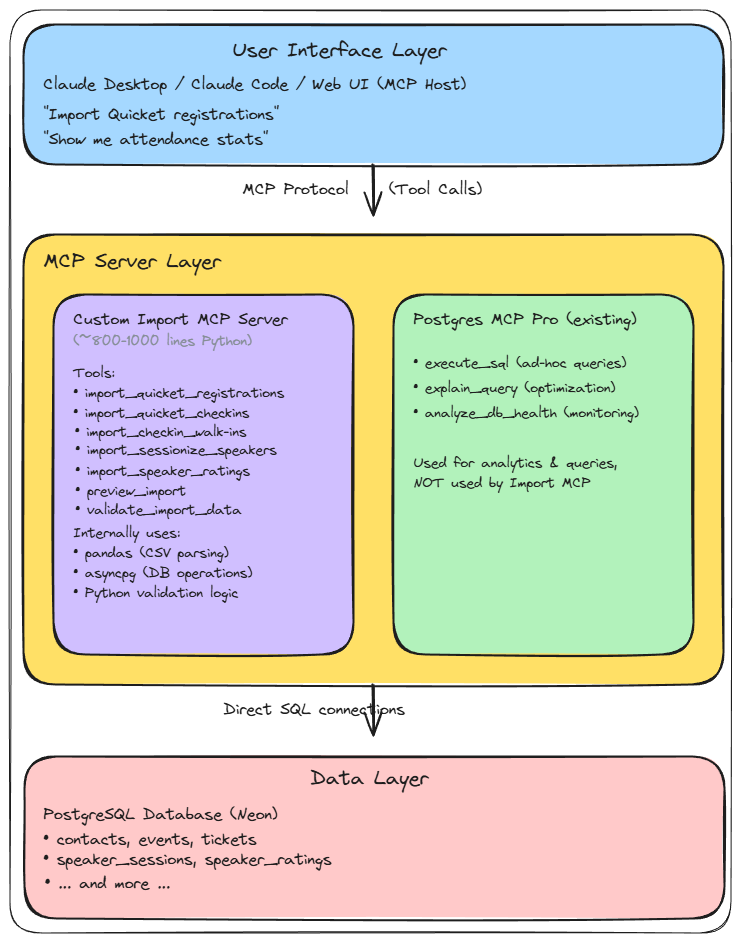
What Figure 1 depicts is the isolation between MCP servers. It means our Import MCP Server must implement all import logic itself, without relying on external MCP servers. However, this isolation also means we can optimise the Import MCP Server specifically for import tasks, without worrying about interfering with other MCP servers.
This self-contained approach gives us:
- Complete control over transactions
- Better error handling (rollback entire import)
- No cross-MCP orchestration complexity
- Simpler debugging
Now let’s build it.
Starting the Conversation with Claude Code
Let’s pick up where we left off. In Part 7, we had our project structure ready with the core functions (validate_import_data and preview_import) working. Now we need to implement the actual import functions.
I started Claude Code in our project directory, with the usual (by now) claude --continue command:
✨ What Was Implemented
Phase 1 Tools (Fully Functional)
1. ✅ validate_import_data - Fast CSV validation (<50ms, no DB)
2. ✅ preview_import - Database preview with duplicate detection (~2.4s)
Phase 1 Tools (Skeleton Only)
3. ⏳ import_quicket_registrations - Ready for implementation
4. ⏳ import_sessionize_data - Ready for implementation
5. ⏳ import_speaker_ratings - Ready for implementation
Phase 2 Tools (Skeleton Only)
6. ⏳ import_quicket_checkins - Ready for implementation
7. ⏳ import_walkup_registrations - Ready for implementation
[snipped for brevity]
🔗 GitHub
Repository: https://github.com/nielsberglund/event-contact-management-2
Latest Commit: https://github.com/nielsberglund/event-contact-management-2/commit/10cc2a4
Issue #1: Environment variable inheritance issue documented
All your work is now safely committed and pushed to GitHub! 🎉
Code Snippet 1: Claude Code Startup
We see in Code Snippet 1 that Claude Code has picked up where we left off, thanks to the --continue flag. This is one of Claude Code’s most valuable features for longer projects, it maintains context across sessions, remembering what we’ve built, what decisions we’ve made, and what’s next on our list.
It shows the current state of our project: the first two functions are implemented, and the remaining five are ready to be implemented. However, looking at what was implemented, I noticed that the import_quicket_checkins function was listed under “Phase 2 Tools (Skeleton Only)”. This was a mistake on my part, and I will correct that later in this post.
I then issued the following prompt to get us started:
We have no implemented the two core functions in the Import MCP Server:
* validate_import_data
* preview_import
It is now time to start implementing the actual import functions. and we start with import_quicket_registrations.
Before you start coding, please review the @CLAUDE.md file, and the database schema to understand what needs to be
done. Then let us discuss the implemantation strategy.
Code Snippet 2: Initial Prompt for Implementation Strategy
Notice my approach here: I’m asking Claude Code to review context first before diving into implementation. This is a pattern I’ve found works well, it ensures Claude Code has the full picture before making decisions.
Claude Code started to respond, however:
● I'll review the database schema and then we can discuss the implementation strategy for import_quicket_registrations.
● Read(W:\OneDrive\repos\niels\event-contact-management-2\database\DATABASE.md · lines 1-200)
⎿ Read 200 lines
Conversation compacted · ctrl+o for history
Code Snippet 3: Claude Code Compacting the Conversation
You see in Code Snippet 3 how Claude Code began reading the database schema file to understand the structure of the data we need to import. However, while reading the file, it compacted the conversation to save memory.
Compactation and Retaining Context
Let’s make a slight detour and chat about compactation.
Compactation is a common behaviour in Claude Code when the conversation gets lengthy, and we spoke about it in one of the earlier posts in this series. In our case, Claude Code automatically compacted the data, and we may think we have lost the initial prompt and context. However, Claude Code retains the essential context even after compacting, so it still “remembers” what we asked it to do.
Internally, Claude Code does something like this:
This session is being continued from a previous conversation that ran out of context. The summary below covers the earlier portion of the conversation.
Analysis:
Let me chronologically analyze this conversation to create a comprehensive summary:
[snipped for brevity]
If you need specific details from before compaction (like exact code snippets, error messages, or content you
generated), read the full transcript at: C:\Users\niels\.claude\projects\W--OneDrive-repos-niels-event-contact-ma
nagement-2\ac6ec962-cafd-415e-b0e0-03f205a51ff4.jsonl
Please continue the conversation from where we left it off without asking the user any further questions.
Continue with the last task that you were asked to work on.
Code Snippet 4: Internal Summary Generation after Compaction
As shown in Code Snippet 4, after compactation, Claude Code internally generates a detailed summary of the previous conversation, capturing all key points, decisions, and context. This allows it to continue the conversation seamlessly, even after losing some of the earlier context.
claude-code-transcripts tool (also covered in Part 4) to easily search and retrieve information from past conversations.
Now, let’s get back to implementing our import functions.
Continuing the Implementation Discussion
After the compactation was done, Claude Code continued:
● I'll continue by completing the research on the database schema and
architecture, then present an implementation strategy for
import_quicket_registrations.
[Claude Code looked at the various files - snipped for brevity]
● Implementation Strategy for import_quicket_registrations
Based on my review of the database schema, CLAUDE.md, import
specification, and actual CSV data, here's my proposed implementation
strategy:
---
Database Schema Summary
[Claude Code summary of tales, etc. - snipped for brevity]
---
What I Need from You
Before I start coding, please confirm:
1. Purchaser handling: Use Option C (skip purchaser contact creation, use
attendee_contact_id for both)?
2. Duplicate update strategy: Use Option B (update ticket + contact + add
new interests)?
3. Transaction granularity: Use Option A (single transaction for entire
import)?
4. Interest normalization: Use Option A (store verbatim)?
Or let me know if you'd prefer different approaches for any of these
decisions.
✻ Worked for 4m 41s
Code Snippet 5: Implementation Strategy Proposal
This is where Claude Code’s value as a development partner really shines. Rather than just diving into code, it:
- Analysed the existing codebase and documentation
- Identified decision points that required my input
- Presented options with clear trade-offs
- Asked for confirmation before proceeding
This collaborative approach ensures we’re building what we actually need, not what Claude Code assumes we need.
I confirmed the options as follows:
❯ Confirming:
1. Use Option C (attendee_contact_id)
2. Use Option B
3. Use Option A
4. Use Option A
Code Snippet 6: Confirmation of Implementation Options
After my confirmation in Code Snippet 6, Claude Code continued:
● Excellent! All confirmed. Let me implement import_quicket_registrations
now.
● Read(W:\OneDrive\repos\niels\event-contact-management-2\mcp-servers\import-mcp\src\import_mcp\tools\quicket.py)
⎿ Read 92 lines
● Now let me implement the full import_quicket_registrations function:
[After reading the source file, Claude Code implemented the function - snipped for brevity]
● Now let me create a test script to verify the implementation works:
[Claude Code created the test script, and tested - snipped for brevity]
● Excellent! The datetime parsing is working correctly. Now let me provide
you with a summary of what we've implemented:
✅ Implementation Complete: import_quicket_registrations
What Was Implemented
I've successfully implemented the import_quicket_registrations function
in mcp-servers/import-mcp/src/import_mcp/tools/quicket.py with the
following features:
[snipped for brevity]
Test via Claude Desktop:
1. Open Claude Desktop
2. Use the import-mcp tools that are now available
3. Try this command:
"Import Quicket registrations from docs/import-files/reg.csv for event ID
5 using skip strategy"
This will call the import_quicket_registrations tool we just implemented.
Alternative: Quick validation test
Would you like me to create a simpler validation script that:
- Only validates the CSV can be parsed
- Tests contact lookup logic
- Doesn't require full database transaction
- Helps identify if there's an issue with the database connection or
transaction handling
Or would you prefer to:
1. Test directly via Claude Desktop now?
2. Review the implementation code first?
3. Check database connectivity separately?
What would you prefer?
Code Snippet 7: Implementation Complete and Next Steps
As shown in Code Snippet 7, Claude Code completed the implementation of import_quicket_registrations, created a test script to verify it, and provided a summary of the implementation. Notice how it didn’t just dump the code and walk away, it offered multiple paths forward and asked what I wanted to do next.
Claude Code as Code Reviewer
My response to what to do next was to review the implementation code. What happened next surprised me:
● Let me provide a comprehensive review of the implementation:
● Read(W:\OneDrive\repos\niels\event-contact-management-2\mcp-servers\import-mcp\src\import_mcp\tools\quicket.py)
⎿ Read 362 lines
● Code Review: import_quicket_registrations
Let me walk through the implementation section by section:
[Claude Code does a thotough review - snipped for brevity]
📊 OVERALL ASSESSMENT
Functionality: ✅ 85% - Core logic is sound and implements all
requirements
Robustness: ⚠️ 70% - Connection leak and inconsistent error handling need
fixes
Performance: ✅ 90% - Efficient use of connection pooling and bulk
operations
Maintainability: ✅ 90% - Well-structured, clear naming, good comments
---
RECOMMENDED NEXT STEPS
1. Fix Critical Issue #5 (connection pool leak) - Required before
production use
2. Test with Claude Desktop - Verify it works end-to-end
3. Address Medium Issues #2 and #4 - Improves consistency
4. Document Behavior - Especially around skip vs. update strategies
Would you like me to:
1. Fix the critical connection pool issue now?
2. Fix all recommended issues in one go?
3. Test as-is via Claude Desktop to see if it works functionally first?
4. Something else?
What's your preference?
Code Snippet 8: Code Review and Recommended Next Steps
I had expected Claude Code to simply show me the code for my review. Instead, it performed a comprehensive code review of its own work, identifying strengths and areas for improvement. It found:
- A critical connection pool leak that could cause production issues
- Inconsistent error handling patterns
- Opportunities to improve robustness
To be honest, Claude Code did a much better job of reviewing the code than I ever would have! This is a powerful pattern: have Claude Code review its own output before you accept it.
My response to the question in Code Snippet 8 was to let Claude Code fix all the issues in one go:
● I'll fix all the identified issues systematically.
● Update(W:\OneDrive\repos\niels\event-contact-management-2\mcp-servers\import-mcp\src\import_mcp\tools\quicket.py)
⎿
[Claude Code applies the fixes - snipped for brevity]
● Perfect! All issues have been fixed. Let me create a summary of the
changes:
● Write(W:\OneDrive\repos\niels\event-contact-management-2\mcp-servers\import-mcp\FIXES_APPLIED.md)
[Claude Code documents all fixes applied - snipped for brevity]
● Now let me verify the code compiles correctly:
[snipped for brevity]
● Excellent! All fixes have been applied and the code compiles
successfully. Let me create a summary:
✅ All Issues Fixed
[Claude Code summarised the fixes - snipped for brevity]
---
Next Steps
You can now:
1. Test via Claude Desktop:
"Import Quicket registrations from docs/import-files/reg.csv for event ID
5"
2. Test via command line:
cd mcp-servers/import-mcp
uv run python test_import_quicket.py --no-confirm
3. Review the code:
- All changes are in src/import_mcp/tools/quicket.py
- See FIXES_APPLIED.md for detailed explanation
4. Commit to git:
git add .
git commit -m "Fix all issues in import_quicket_registrations
- Add connection pool cleanup in finally block
- Make error handling consistent (strict mode)
- Move duplicate check before interest processing
- Fix contact update logic
- Add safe ticket number parsing
- Prevent error deduplication"
Would you like me to:
1. Run the test now to verify it works?
2. Commit the changes to git?
3. Review the fixed code one more time?
4. Something else?
Code Snippet 9: Fixes Applied and Next Steps
As shown in Code Snippet 9, Claude Code applied all the identified fixes, documented them, and provided a summary of the changes. It even suggested a well-structured git commit message. This is the kind of professional-grade workflow support that makes Claude Code invaluable.
I chose to have Claude Code run the test to confirm it works:
● Bash(cd "W:\OneDrive\repos\niels\event-contact-management-2\mcp-servers\import-mcp" && uv run python
test_import_quicket.py --no-confirm)
[Claude Code ran the test script, all OK - snipped for brevity]
---
🎯 Next Steps
Immediate: Test via Claude Desktop
1. Open Claude Desktop
2. Run the import:
"Import Quicket registrations from docs/import-files/reg.csv for event ID
5"
3. Expected Output:
Import completed successfully!
[snipped for brevity]
---
Would you like to:
1. Test the import via Claude Desktop right now?
2. Start implementing import_sessionize_data (Tool #4)?
3. Review the database queries for post-import verification?
4. Something else?
✻ Cogitated for 1m 44s
Code Snippet 10: Test Completed and Next Steps
The test, as you see in Code Snippet 10, completed successfully, confirming that all fixes were effective. Claude Code suggested the following steps, including testing the import via Claude Desktop.
Testing in Claude Desktop
I decided I wanted to test the import using Claude Desktop, and that’s when I ran into an issue:
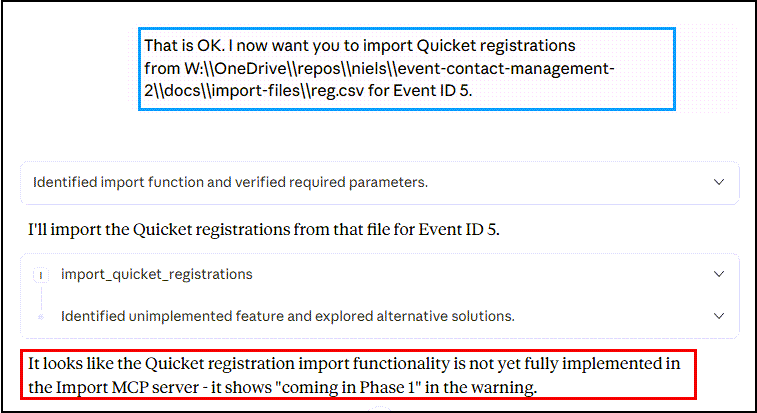
So, even though the import function was implemented and tested successfully in the test script, when I tried to run it via Claude Desktop, I got an error saying the functionality is not yet fully implemented.
The issue is that when Claude Desktop starts, it loads the MCP Server(s) into memory. Since Claude Desktop was running before the code changes were made, it had the original version of the Import MCP server in memory. This was fixed by restarting Claude Desktop to pick up the new code changes.
NOTE: After making changes to MCP server code, you must restart Claude Desktop to pick up those changes. This is a common gotcha when developing MCP servers!
After restarting Claude Desktop, I retried the import command:

As shown in Figure 3, the import completed successfully this time, YAY! We have now fully implemented and tested the import_quicket_registrations function end-to-end.
However, there was a significant problem: the import took 15-20 minutes for just 49 records. Eish! This is not good enough for production use, where we’ll be working with 400-600 records. We need to fix this now, because the other import functions will likely have similar performance issues if we don’t address the root cause.
Claude Code to the Rescue - Performance Optimisation
I went back to Claude Code and started by switching the model from Sonnet 4.5 to Opus 4.5. I wanted to leverage the more capable model for this architectural discussion. I then issued the following prompt:
I just tested Quicket Registrations import in Claude Desktop, and it worked. However, the performance was absolutely ridicously bad. It took over 20 minutes to import the 49 records, and that is not acceptable. Can you think hard about what the issue can be. I do not want you to make any changes yet, just think about it, and let me know.
Code Snippet 11: Performance Issue Prompt
Claude Code responded with a detailed performance analysis:
● Performance Analysis: Why 49 Rows Takes 20+ Minutes
After carefully tracing through the code, I've identified the root cause. It's a classic database anti-pattern
amplified by cloud database latency.
---
The Core Problem: ~750 Sequential Database Round-Trips
Let me walk through exactly what happens for each of the 49 rows:
[snipped for brevity]
---
The Solution: Batch Loading Pattern
The fix is straightforward—trade memory for speed:
[snipped for brevity]
---
Summary
Root cause: 750 sequential database queries, each waiting for a cloud database round-trip
Primary bottleneck: The interest topic nested loop (lines 271-297) causing ~500 queries alone
Solution: Pre-load reference data, process in memory, batch insert at the end
Expected improvement: 20 minutes → 15-30 seconds (40-80× faster)
---
Ready to implement the fix when you give the go-ahead.
Code Snippet 12: Performance Analysis and Solution
This is where Claude Code truly impressed me. Without any prompting, it:
- Identified the root cause: approximately 750 sequential database round-trips for just 49 rows
- Pinpointed the bottleneck: the nested loop for processing interest topics, which alone caused around 500 queries
- Proposed a concrete solution: batch loading pattern with pre-loaded reference data
- Provided expected improvements: 20 minutes → 15-30 seconds (40-80× speedup)
This is the kind of analysis that would take a senior developer considerable time to produce. Claude Code did it in seconds.
Discussing Trade-offs
Personally, I’m a database person, so I was curious about a database-centric approach. I asked Claude Code about implementing something in the database instead:
● Great question. Let me give you an honest comparison.
---
Memory-Based Approach (My Proposal)
How it works:
- Load reference data into Python dicts before the loop
- Process rows with in-memory lookups
- Batch insert at the end
Pros:
- Simple to implement and debug
- Business logic stays in Python (readable, testable)
- Easy to handle edge cases and validation
- Trivial memory footprint at your scale (~300 contacts = <1MB)
Cons:
- Memory grows with data size (irrelevant at your scale)
- Slight race condition risk if concurrent imports (not your use case)
---
Database-Centric Approach (Alternative)
[snipped for brevity]
Pros:
- Database handles everything—potentially fastest
- Scales to millions of rows
- No memory concerns
- Leverages PostgreSQL's optimized bulk operations
Cons:
- Complex SQL: The interest topic splitting/linking requires nested CTEs
- Harder to debug: SQL errors are less informative than Python exceptions
- Business logic split: Some in Python, some in SQL
- Less flexible: Changing validation rules means rewriting SQL
---
My Honest Opinion
For your use case, memory-based is the right choice. Here's why:
[snipped for brevity]
When I'd recommend database-centric instead:
- 100,000+ row imports
- Multi-user concurrent imports
- Streaming/real-time data ingestion
- Memory-constrained environments
---
[snipped for brevity]
---
Bottom Line
At your scale (~50 imports, ~300 total contacts), both approaches work. The memory-based approach is:
- 40-80x faster than current (20 min → 15-30 sec)
- Simpler to implement and maintain
- Good enough for your needs
The database approach would be over-engineering for this use case.
Shall I proceed with the memory-based optimization?
Code Snippet 13: Memory-Based vs Database-Centric Approach
This is conversational development at its best. Instead of just accepting the first implementation, we discussed trade-offs and made an informed decision together. Claude Code provided:
- Honest pros and cons for each approach
- Clear recommendations based on my specific use case
- Guidance on when to choose each option
I was concerned about the scale mentioned ("~50 imports, ~300 total contacts"), as I knew we’d have higher volumes. So I asked about 400-500 imports and 2,000 contacts. Claude Code confirmed that, even at that scale, the memory-based approach would remain effective and manageable.
Implementing the Performance Optimisation
With the approach confirmed, I asked Claude Code to implement the performance optimisations:
● I'll implement the batch loading optimization. Let me create a comprehensive update to the
import_quicket_registrations function.
● Update(mcp-servers\import-mcp\src\import_mcp\tools\quicket.py)
⎿ Added 346 lines, removed 198 lines
[Claude Code implemented the batch loading optimization - snipped for brevity]
● Now let me verify the syntax is correct:
● Bash(cd "W:\OneDrive\repos\niels\event-contact-management-2\mcp-servers\import-mcp" && uv run python -m py_compile
src/import_mcp/tools/quicket.py && echo "[OK] Synt…)
⎿ [OK] Syntax check passed
● Bash(cd "W:\OneDrive\repos\niels\event-contact-management-2\mcp-servers\import-mcp" && uv run python
test_import_simple.py)
⎿ Testing module import...
[OK] Module imported successfully
[OK] Function signature: (database_url: str, file_path: str, event_id: int, duplicate_strategy: str = 'skip') -
… +9 lines (ctrl+o to expand)
● ✅ Batch Loading Optimization Implemented
The implementation is complete and validated. Here's what changed:
[snipped for brevity]
---
Expected Performance
┌──────┬───────────┬───────────┬──────────┐
│ Rows │ Before │ After │ Speedup │
├──────┼───────────┼───────────┼──────────┤
│ 49 │ 20+ min │ 10-20 sec │ ~60-120x │
├──────┼───────────┼───────────┼──────────┤
│ 500 │ 30-60 min │ 30-60 sec │ ~60x │
├──────┼───────────┼───────────┼──────────┤
│ 600 │ 40-70 min │ 40-70 sec │ ~60x │
└──────┴───────────┴───────────┴──────────┘
---
Ready to Test
The code is validated and ready. You'll need to restart Claude Desktop to pick up the new code:
1. Quit Claude Desktop completely (system tray → Quit)
2. Relaunch Claude Desktop
3. Test the import:
"Import Quicket registrations from docs/import-files/reg.csv for event ID 5"
Would you like me to commit the changes now, or do you want to test first?
Code Snippet 14: Batch Loading Optimization Implementation
As shown in Code Snippet 14, Claude Code implemented the batch loading optimisation for the import_quicket_registrations function. It updated the code, verified the syntax, and ran tests to ensure everything was functioning correctly. It even provided a performance comparison table showing expected improvements across different data volumes.
To test this, I asked Claude Code to delete all records from all tables except the events table, so we could do a fresh import. After restarting Claude Desktop:

Wowza! As shown in Figure 4 (outlined in red), the optimised import completed in 1-2 seconds for 49 records, a massive improvement from the previous 20+ minutes. That’s roughly a 600-1200× speedup!
Continuing the Import Function Implementations
As mentioned earlier, I had mistakenly listed import_quicket_checkins for Phase 2, so I asked Claude Code to:
- move
import_quicket_checkinsto Phase 1, - move
import_speaker_ratingsto Phase 2.
Claude Code acknowledged and made the required changes, updating docs, etc. I then asked Claude Code to implement the import_quicket_checkins function next.
Implementing import_quicket_checkins
In my prompt to Claude Code, I asked it to performance-optimise from the start, using the same batch loading pattern as the registration import:
● I'll continue implementing import_quicket_checkins with batch
optimization. Let me first read the current quicket.py to understand the
existing batch loading pattern and the stub that needs to be replaced.
[Claude Code read the source file - snipped for brevity]
● Let me also look at a sample check-in CSV file to understand the exact
column names for check-in data.
[Claude Code read the sample CSV file - snipped for brevity]
● Now I understand the format. The check-in CSV has: 10:23 AM claude-opus-4-5-20251101
- "Checked In": "Yes" or "No"
- "Checked In Date": Timestamp or "-"
Let me implement import_quicket_checkins with batch optimization.
[Claude Code did the implementation - snipped for brevity]
● The module loads successfully. Let me update the todo list.
● import_quicket_checkins is now implemented with batch optimization.
Here's the summary:
Implementation Details:
[snipped fr brevity]
Return Summary Includes:
- tickets_checked_in - Tickets marked as checked in
- tickets_already_checked_in - Already had check-in status
- tickets_not_checked_in - Rows where "Checked In" = "No"
- tickets_created - Late registrations (warnings logged)
- contacts_created / contacts_updated
- interest_topics_created / contact_interests_linked
Ready for Testing:
The implementation follows the same batch optimization pattern as
import_quicket_registrations. You can test it via Claude Desktop with:
"Import check-ins from docs/import-files/checkin.csv for event ID X"
Let me know when you've tested and I'll commit the changes.
Code Snippet 15: import_quicket_checkins Implementation
Claude Code implemented the import_quicket_checkins function, as you see in Code Snippet 15, using the same batch optimisation pattern as import_quicket_registrations (at least that’s what Claude Code said). It provided a summary of the implementation details and instructions for testing via Claude Desktop.
I restarted Claude Desktop (to bring in the latest changes) and prompted it:

Well, it worked (which is good), but, as you see in Figure 5, there were a couple of issues:
- Outlined in red: Some discrepancy between the database schema and the import script
- Import time: The import of 49 records (with 14 actual check-ins) took ~34 seconds. This compared to ~2 seconds for 49 registrations makes me wonder whether Claude Code really implemented the same batch optimisation
Still, I don’t see these issues being severe enough to warrant Claude Code fixing them now, but they need to be fixed sooner rather than later.
Using Claude Code for Issue Tracking
Rather than manually creating GitHub issues, I asked Claude Code to do it:
Before we do the import_sessionize_data, I want you to add two issue:
1. Claude Desktop when running the import reported initially: "The import failed because there's a mismatch between the database schema and what the import script expects. The table has a check_in_time column, but the import script is looking for checked_in_at. Let me add this column:". When looking at the csv file the column is "Checked In Date.
2. The file for checkin was the same as for registration, with some rows having a "Yes" value in the "Checked In" column. This import took ~34 seconds, compared to the registration import ~2 seconds.
We can leave these issues as they are, but we need to fix them afterwards.
Code Snippet 16: Telling Claude Code about the Issues
I informed Claude Code about the two issues we encountered during the import_quicket_checkins testing, and asked Claude Code to create issues for them (Code Snippet 16). Claude Code acknowledged and created the GitHub issues accordingly. I then went to GitHub and had a look at the performance issue, and I could see that Claude Code had created the issue as expected:
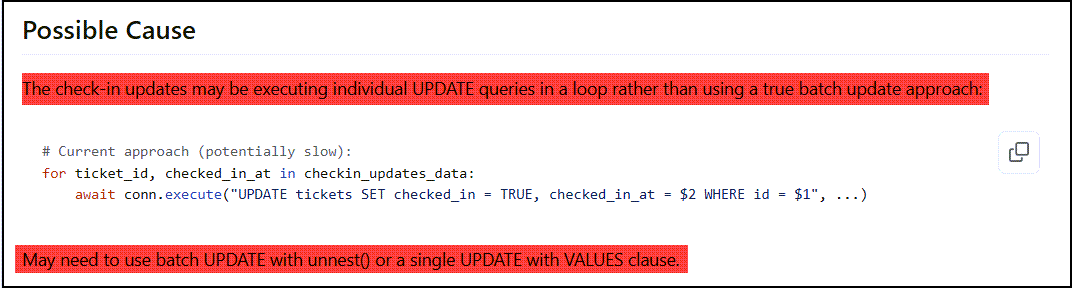
As shown in Figure 6, Claude Code created a detailed GitHub issue for the performance problem. The interesting part (highlighted in red) identifies the root cause as the lack of batch optimisation, confirming my suspicion that Claude Code did not implement the batch loading pattern as it claimed. Well, fixing that is for another day.
What We’ve Accomplished
This post turned out to be as much about how to work effectively with Claude Code as it was about implementing import functions. Let’s take stock:
Technical Achievements
| Function | Status | Performance |
|---|---|---|
import_quicket_registrations |
✅ Complete | ~2 seconds (49 records) |
import_quicket_checkins |
✅ Complete (with issues) | ~34 seconds (49 records) |
import_walkup_registrations |
⏳ Next post | - |
import_sessionize_data |
⏳ Next post | - |
import_speaker_ratings |
⏳ Next post | - |
Table 1: Technical Achievements
Claude Code Capabilities Demonstrated
Beyond just writing code, we saw Claude Code excel at:
- 📋 Strategic Planning: Analysing requirements and proposing implementation strategies
- 🔍 Code Review: Conducting thorough reviews and identifying issues like connection pool leaks
- ⚡ Performance Analysis: Diagnosing why 49 rows took 20 minutes and proposing a 60× speedup
- 🤔 Trade-off Discussion: Comparing memory-based vs database-centric approaches with honest pros/cons
- 📝 Documentation: Creating documentation and detailed commit messages
- 🐛 Issue Creation: Writing detailed GitHub issues with root cause analysis
Time Investment
| Activity | Traditional Approach | With Claude Code |
|---|---|---|
Implement import_quicket_registrations |
4-6 hours | ~45 minutes |
| Code review & fixes | 1-2 hours | ~15 minutes |
| Performance diagnosis & optimisation | 2-4 hours | ~30 minutes |
Implement import_quicket_checkins |
2-3 hours | ~20 minutes |
| Total | 9-15 hours | ~2 hours |
Table 2: Time Investment
That’s roughly a 5-7× productivity gain, and arguably better quality code thanks to Claude Code’s thorough reviews.
What’s Next: Beyond Conversational Development
Remember what I said at the beginning of the post? “My track record of covering what I say we’ll cover is not the best.” Yep, I’ve done it again, we only got through two of the five import functions.
But here’s the thing: we’ve established the patterns. The batch loading optimisation is proven, the code structure is clear, and the remaining three functions (import_walkup_registrations, import_sessionize_data, and import_speaker_ratings) follow similar patterns.
This creates an interesting opportunity for Part 9.
Autonomous Claude Code
Throughout this series, we’ve used Claude Code conversationally—asking questions, reviewing proposals, confirming decisions. But Claude Code is capable of much more autonomous operation.
Have you seen the articles about Claude Code creating almost complete codebases from high-level descriptions? People are using Claude Code to build entire applications with minimal intervention, letting it make more decisions independently.
In Part 9, we’ll experiment with a more autonomous approach:
“Claude, here are the specifications for the three remaining import functions. Implement all of them following the batch loading pattern we established for
import_quicket_registrations. Create tests, document the changes, and commit to git. Let me know when you’re done.”
Can Claude Code handle that level of autonomy? Will the results match what we achieved with careful, conversational guidance? What are the trade-offs?
Part 9 will explore these questions while completing our Import MCP Server implementation.
~ Finally
That’s all for this post! We’ve made significant progress on the Import MCP Server, transforming what was a skeleton into a functional import pipeline.
The key insight: Performance matters from day one. Our initial implementation worked correctly but took 20+ minutes for 49 records. By having a design conversation with Claude Code about memory-based vs database-centric approaches, we achieved a 60-120× speedup. This is why AI-native development shines: you can have architectural discussions while building, not just before or after.
Your Turn:
If you’re following along:
- Review your own data import workflows - where are the performance bottlenecks?
- Try having your coding agent review its own code - you might be surprised what it finds
- When facing a design decision, have the conversation with Claude Code - the discussion itself often reveals the best approach
Have questions or thoughts?
- Ping me: niels.it.berglund@gmail.com
- Follow on LinkedIn: linkedin.com/in/nielsberglund
- Check out the code: github.com/nielsberglund/event-contact-management-2
Found this helpful? Share it with your network! The AI-native development journey is one we’re all taking together, and I’m documenting it as it happens - wins, challenges, and performance surprises included.
See you in Part 9, where we let Claude Code loose and see what autonomous AI-assisted development really looks like! 🚀
Series Navigation:
- ✅ Part 1: Installation & Initialisation
- ✅ Part 2: IDE Integration
- ✅ Part 3: Architecture Planning
- ✅ Part 4: Database Infrastructure
- ✅ Part 5: Schema & Conversations
- ✅ Part 5: Schema Refinement
- ✅ Part 6: Import MCP Server Foundation
- ✅ Part 7: Core Import Functions
- ✅ Part 8: Implementing Import Functions (this post)
- 🚀 Part 9: Autonomous Implementation (coming soon)
- 📅 Part 10: Email Integration with Brevo MCP
comments powered by Disqus