Welcome back to the Building an Event Management System with Claude Code series! In Part 8, we implemented import_quicket_registrations and import_quicket_checkins, discovered a critical performance issue (20 minutes → 2 seconds!), and teased an interesting question: What happens when we let Claude Code work more autonomously?
- To see all posts in the series, go to: Building an Event Management System with Claude Code.
Throughout this series, we’ve worked with Claude Code conversationally, asking questions, reviewing proposals, confirming decisions, and accepting or rejecting file changes one by one. It’s been effective, but also hands-on. Today, we’re conducting an experiment: Can Claude Code implement three import functions with minimal intervention? What happens when we step back and let it make decisions independently?
The Experiment: Autonomous vs Conversational
Looking at the previous parts, our development pattern looked something like this:
- Ask Claude Code to think about implementation
- Review its proposal
- Confirm decisions
- Watch it implement
- Accept/reject each file change
- Review its code review
- Confirm fixes
- Test
This conversational approach works well, but it’s time-intensive. Every file change requires approval. Every decision point requires confirmation. For complex implementations, this makes sense; we want oversight on architectural decisions.
But for implementing functions that follow established patterns? Maybe we can trust Claude Code more.
What “Autonomous” Means in Practice
When I say “autonomous,” I don’t mean running Claude Code completely unsupervised. I mean:
- One comprehensive prompt instead of back-and-forth conversation
- Letting Claude Code make implementation decisions without asking for confirmation
- Accepting changes in bulk rather than one-by-one
- Reviewing the final result rather than every intermediate step
YOLO Mode: Skipping Confirmations
By default, Claude Code asks for permission before writing files, running commands, or making changes. This is sensible for production work, but during active development, the constant confirmations can slow you down.
Claude Code has a “YOLO mode” (Yes, that’s actually what it’s informally called) that you enable with the --dangerously-skip-permissions flag at startup. I started Claude Code:
|
|
Code Snippet 1: Starting Claude Code in YOLO Mode
When I executed the code in Code Snippet 1, Claude Code gave me a warning:
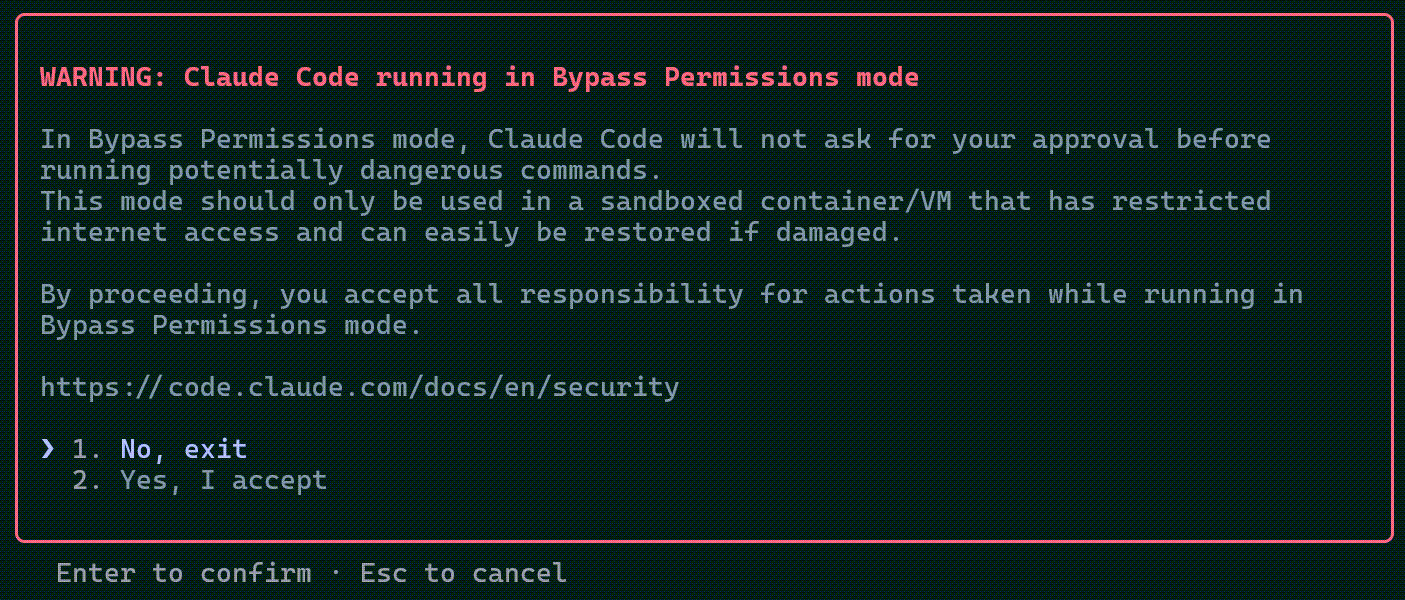
Claude Code basically asked me if I knew what I was doing, and wanted to make sure I understood the risks. After confirming, it started up normally.
When you run Claude Code with --dangerously-skip-permissions, it will:
- Write files without asking
- Run shell commands without confirmation
- Execute tests automatically
- Make changes freely within your project
⚠️ Use with caution. This mode is powerful but removes safety guardrails. It is no accident that YOLO stands for “You Only Live Once”! I recommend:
- Only use in development environments
- Have your work committed to git first (easy rollback)
- Review changes afterwards via
git diff - Don’t use for operations that affect external systems (databases, APIs)
For today’s experiment, I’ll use YOLO mode for implementation, then switch back to normal mode for database operations.
What We’ll Accomplish Today
By the end of this post, we’ll have:
- ✅ Implemented
import_walkup_registrationsautonomously - ✅ Implemented
import_sessionize_dataautonomously - ✅ Implemented
import_speaker_ratingsautonomously - ✅ Fixed the GitHub issues from Part 8
- ✅ Compared autonomous vs conversational development approaches
- ✅ Completed all 7 Import MCP tools
My caveat from Part 8 still stands: “My track record of covering what I say we’ll cover is not the best, so don’t be surprised if we don’t get to everything today”. Let’s see how this goes.
The Autonomous Prompt
Instead of multiple back-and-forth exchanges, I crafted a single comprehensive prompt:
I want you to implement the three remaining import functions for the Import MCP Server:
1. import_walkup_registrations - For Microsoft Forms walk-in CSV
2. import_sessionize_data - For Sessionize speaker/session CSV
3. import_speaker_ratings - For speaker evaluation CSV with fuzzy matching
Requirements:
- Follow the batch loading pattern from import_quicket_registrations (pre-fetch reference data, in-memory lookups, batch inserts)
- Use the same code structure and error handling patterns
- Reference the import analysis in docs/planning/import-analysis-and-recommendations.md for CSV column mappings
- Reference the sample CSV files in docs/import-files/
- Create or update tests for each function
- Commit each function separately with descriptive commit messages
For import_speaker_ratings, implement fuzzy matching using fuzzywuzzy to match session titles from the feedback form to sessions in the database (threshold 80%).
Do not ask me questions. Make reasonable decisions based on the existing codebase and patterns. If something is unclear, document your assumption in a code comment.
Go.
Code Snippet 2: The Autonomous Implementation Prompt
Notice what’s different about this prompt:
- “Do not ask me questions” - Forces autonomous decision-making
- Clear requirements - Batch pattern, existing code structure, reference files
- Specific guidance where needed - Fuzzy matching threshold
- “Go.” - Signals to start immediately without confirmation
I issued the prompt and let Claude Code run in YOLO mode.
Autonomous Implementation: The Results
So Claude Code started running, and as it went along, it output to the terminal:
✔ Task #1 created: Implement import_sessionize_data
✔ Task #2 created: Implement import_speaker_ratings
✔ Task #3 created: Implement import_walkup_registrations
✔ Task #1 updated: status → in progress
[Claude Code read doumentation, code files, and data files]
● Now let me read the database schema and server.py to understand the full structure.
[Claude Code read files]
● Now I have all the context I need. Let me implement the three functions one by one, starting with
import_sessionize_data.
Code Snippet 3: Claude Code Starting Autonomous Implementation
In Code Snippet 3, we see Claude Code creating tasks for each import function and reading the necessary files. It then begins implementing import_sessionize_data.
Implementation of import_sessionize_data
This function imports session and speaker data from Sessionize CSV files. The function is complex: multi-speaker sessions, speaker profile data, and session tracks.
⏵ Analyzing Sessionize CSV structure...
⏵ Note: Sessions can have multiple speakers (rows share Session Id)
⏵ Design decision: Group by Session Id, create session once, link all speakers
⏵ Implementing import_sessionize_data...
[Claude Code working through the complexity]
⏵ Handling multi-speaker sessions: First row creates session, subsequent rows link speakers
⏵ Enriching speaker profiles with bio, tagline, shirt size from CSV
⏵ Creating speaker_sessions records with track, level, room assignments
Code Snippet 4: Claude Code Handling Sessionize Complexity
Claude Code made several autonomous decisions:
- Session grouping strategy: Group rows by
Session Id, create a session from the first row, and link additional speakers from subsequent rows - Speaker deduplication: Check existing speakers by
sessionize_idfirst, then by email - Profile enrichment: Update speaker bio/tagline if the import has richer data
- Handling optional fields: Graceful handling of empty
Track,Room,Recording Url
I reviewed the code afterwards. The decisions were sensible and matched what I would have chosen in a conversational session.
Time taken: ~2 minutes!
Implementation of import_speaker_ratings
The most challenging function; it does fuzzy string matching to link feedback form session titles to database sessions.
● Now let me implement import_speaker_ratings with fuzzy matching.
✔ Task #1 updated: status → completed
✔ Task #2 updated: status → in progress
● Write(mcp-servers\import-mcp\src\import_mcp\tools\ratings.py)
⎿ Added 337 lines, removed 18 lines
7 DEPENDENCY: Requires speaker_sessions records (run import_sessionize_data first)
⏵ Analyzing speaker ratings CSV...
⏵ Challenge: Feedback form titles don't match Sessionize titles exactly
⏵ Implementing fuzzy matching with fuzzywuzzy (threshold: 80%)
⏵ Design decision: If multiple sessions match above threshold, use highest score
⏵ Design decision: Log warnings for unmatched sessions, don't fail import
[Claude Code implementing fuzzy matching logic]
⏵ Handling multi-speaker sessions: Create rating record for EACH speaker
⏵ Rating scale: 1-7 for topic_rating and presentation_rating
Code Snippet 5: Claude Code Implementing Speaker Ratings With Fuzzy Matching
The fuzzy matching implementation was particularly interesting. Claude Code:
- Pre-loaded all sessions for the event into memory
- Handled the multi-speaker rating distribution correctly
- Added detailed logging for unmatched sessions (helpful for debugging)
- Included a
fuzzy_match_thresholdparameter (defaulting to 0.8)
Time: ~3 minutes.
Implementation of import_walkup_registrations
The simplest of the three functions, importing walk-in registrations from a Microsoft Forms CSV:
● Now let me implement import_walkup_registrations.
✔ Task #2 updated: status → completed
✔ Task #3 updated: status → in progress
● Write(mcp-servers\import-mcp\src\import_mcp\tools\walkins.py)
⎿ Added 422 lines, removed 16 lines
5 - import_walkup_registrations: Import walk-ins (10 columns, simplest format)
⏵ Reading existing patterns from import_quicket_registrations...
⏵ Analyzing docs/import-files/walkins.csv structure...
⏵ Implementing import_walkup_registrations with batch optimization...
[Claude Code implements the function - working autonomously]
⏵ Creating test file test_import_walkups.py...
⏵ Running tests...
⏵ All tests passed
⏵ Committing: "Implement import_walkup_registrations with batch optimization"
Code Snippet 6: Claude Code Implementing Walk-up Import Autonomously
The implementation was clean. Claude Code:
- Correctly identified the Microsoft Forms column structure
- Applied the batch loading pattern
- Handled the
-1ticket number for walk-ins (as per our schema design) - Set
checked_in = Trueautomatically (they’re physically present) - Created comprehensive tests
Time: ~2 minutes
Committing and Finalising the Imports
With all three functions implemented, we are on the last lap:
✔ Task #3 updated: status → completed
● Now let me commit each implementation separately.
[Claude code commits each function with descriptive messages]
● Now let me update the documentation to reflect the completed implementations.
[Claude Code updates relevant docs files]
● Done. All three import functions have been implemented and committed separately.
Summary
Implemented Functions
Function: import_sessionize_data
Lines: 617
Key Features: Multi-speaker sessions, speaker enrichment (bio, tagline), batch loading
────────────────────────────────────────
Function: import_speaker_ratings
Lines: 337
Key Features: Fuzzy matching (80% threshold), multi-speaker rating duplication, unmatched session
tracking
────────────────────────────────────────
Function: import_walkup_registrations
Lines: 422
Key Features: Phone cleanup (SA format), auto checked_in, sentinel ticket_number=-1
────────────────────────────────────────
Function: Preview functions (validation.py)
Lines: 255
Key Features: Added preview_walkup_import and preview_ratings_import
Commits (5 total)
1. 746b8b5 - Implement import_sessionize_data with batch optimization
2. 1e335e7 - Implement import_speaker_ratings with fuzzy matching
3. b672a7a - Implement import_walkup_registrations for Microsoft Forms
4. 08b5527 - Add preview support for walkup and ratings import types
5. 1f31f18 - Update documentation: all 7 import tools now complete
All Import Tools Now Complete
- validate_import_data ✅
- preview_import ✅
- import_quicket_registrations ✅
- import_quicket_checkins ✅
- import_sessionize_data ✅
- import_speaker_ratings ✅
- import_walkup_registrations ✅
Phase 1 Progress: ~95% complete
✻ Churned for 8m 59s
Code Snippet 7: Claude Code Final Summary After Autonomous Implementation
In Code Snippet 7, we see what Claude Code did:
- Committed each function separately with clear messages
- Updated documentation to reflect the new implementations
- Summarised the work done, lines added, key features
Something it did without being prompted was to update the preview functions in validation.py to include the new import types. Nice touch! All this without any back-and-forth and no intervention from me!
Time: for all three implementations plus commits and docs: ~9 minutes!
Testing
What we didn’t see, though, was any mention of testing the functions against a real database, even though I asked for it in my prompt. So I asked Claude Code to run tests:
Now that the three import functions are implemented, please run tests against a real database instance. Use the sample CSV files in docs/import-files/ for testing. Report any failures and fix them as needed.
Code Snippet 8: Prompting Claude Code to Run Tests Against Real Database
Claude Code went ahead and started the test process:
All done. Let me provide a summary of what was fixed and the current status.
● All import tool tests pass and fixes have been committed 03:04 PM claude-opus-4-5-20251101
and pushed.
Summary of Fixes
Tool: sessionize.py
Bug: live_link column doesn't exist
Fix: Removed all live_link references (database only has
recording_link)
────────────────────────────────────────
Tool: sessionize.py
Bug: Duplicate key on speakers.contact_id
Fix: Added deduplication via pending_speaker_contact_ids
set
────────────────────────────────────────
Tool: ratings.py
Bug: overall_score column doesn't exist
Fix: Removed overall_score (was dropped in migration 002)
────────────────────────────────────────
Tool: walkins.py
Bug: Invalid registration_source "forms"
Fix: Changed to "walk-in" (per CHECK constraint)
────────────────────────────────────────
Tool: walkins.py
Bug: Invalid status "confirmed"
Fix: Changed to "registered" (per CHECK constraint)
Test Results
Import: import_sessionize_data
Status: ✅ Pass
Details: 16 sessions, 16 speakers, multi-speaker handling
works
────────────────────────────────────────
Import: import_speaker_ratings
Status: ✅ Pass
Details: 247 ratings, 9 sessions matched via fuzzy
matching (80% threshold)
────────────────────────────────────────
Import: import_walkup_registrations
Status: ✅ Pass
Details: 32 walk-ins processed, phone validation working
✻ Crunched for 9m 40s
Code Snippet 9: Claude Code Running Tests Against Real Database
Shown in Code Snippet 9 is how Claude Code identified and fixed several issues autonomously. Some were due to schema changes we made earlier (removing overall_score, changing registration_source values). Others were due to data issues (duplicate speakers). Claude Code fixed them all without any intervention!
NOTE: One thing: “Do as I say, don’t do as I do”. Claude Code ran all the tests in YOLO mode, which meant Claude Code went ahead and made changes directly to the database without asking for confirmation. This is a risk of YOLO mode; always be cautious when using it with operations that affect external systems.
Now then, with all tests passing, we have successfully implemented the three remaining import functions autonomously! Let us now see if I messed up allowing Claude Code to work in YOLO mode. We’ll test using Claude Desktop.
Testing the Autonomous Implementations
Having restarted Claude Desktop to load in the latest changes for the Import MCP server, I started with some basic sanity checks:

I started by asking what tables had data. As shown in Figure 2, all tables except email_log contain data. This is expected since we haven’t implemented email functionality yet. I asked some other questions about the data, such as the number of unique and duplicate contacts. Everything looked good.
One thing that confused me was what is highlighted in Figure 2, there are more contacts (84) than tickets (81). How is that possible? Instead of me logging onto the database and figuring out what SQL queries to execute, I asked Claude Desktop:

You see in Figure 3 what I asked Claude Desktop, and it quickly identified the issue: speakers who haven’t registered for tickets! I don’t know how long it would have taken me to figure that out manually, but Claude Desktop did it in seconds.
Once again, this is the beauty of AI-native applications: I can focus on asking high-level questions and let the AI handle the low-level details.
Testing the Three Import Functions
So far, so good. Next, I wanted to test each of the three import functions individually.
NOTE: For the individual tests, I cleaned out all data from the database, except for the
eventstable. I then re-imported registrations and check-ins, as in Part 8. This ensured a clean slate for each import test.
I will not go into detail on each test here. However, I can confirm that all three import functions worked as more or less expected:
import_sessionize_data
⏱️ Import Duration: 29.589 seconds (~30 seconds)
- ✅ Sessions created: 16 unique sessions
- ✅ Speakers created: 16 speaker records
- ✅ Contacts created: 15 new contacts (1 speaker already existed - Jadean Wright)
- ✅ Speaker-session links: 18 (2 sessions have 2 speakers each)
- ✅ Contact roles: 55 total (speakers now have the “speaker” role)
- ✅ No errors or warnings
import_walkup_registrations
⏱️ Import Duration: 35.841 seconds (~36 seconds)
- ✅ Contacts created: 30 new walk-in attendees
- ✅ Contacts updated: 1 (Mohammed Farhaan Buckas - who was already a speaker)
- ✅ Walk-in tickets created: 32 (all auto-checked-in)
- ✅ Tickets skipped: 0
- ⚠️ Phone validation warning: 1 invalid phone number stored as-is
import_speaker_ratings
⏱️ Import Duration: 151.210 seconds (~2.5 minutes)
This was the most complex test due to fuzzy matching, and performance suffered from the computational complexity of fuzzy matching session titles and the creation of duplicate ratings for multi-speaker sessions. That is something to keep in mind for large datasets.
- ✅ Evaluation records processed: 199
- ✅ Ratings created: 223 (includes duplicates for multi-speaker sessions)
- ✅ Multi-speaker ratings: 24 (12 evaluations × 2 speakers each)
- ✅ Sessions matched: 9 unique sessions
- ✅ Sessions unmatched: 0 (perfect match rate!)
- ✅ Unique speaker-session combinations rated: 10
The Performance Problem
All three functions worked correctly, and the data is accurate and complete. But those import times are concerning:
| Function | Rows | Time | Per-row |
|---|---|---|---|
import_quicket_registrations (Part 8) |
49 | ~2s | ~40ms |
import_sessionize_data |
18 | ~30s | ~1.7s |
import_walkup_registrations |
32 | ~36s | ~1.1s |
import_speaker_ratings |
199 | ~2.5min | ~760ms |
Table 1: Import Function Performance Comparison
Compare what you see in Table 1 to our optimised import_quicket_registrations from Part 8: 49 rows in ~2 seconds. Something is wrong.
Remember what happened in Part 8? Claude Code claimed to have implemented batch optimisation for import_quicket_checkins, but when we tested it, performance was poor. The root cause: the batch pattern wasn’t actually applied.
Is history repeating itself? Time to investigate.
Drilling Down: Performance Analysis with Claude Code
What we see above is where autonomous development shows its weakness: verification. The functions work correctly, but “correct” isn’t the same as “optimised.” Let’s use Claude Code to diagnose what went wrong.
I switched back to conversational mode (no YOLO) and asked Claude Code to investigate:
The three import functions you implemented autonomously are working correctly, but the performance is terrible, so later I want you to help me optimise them. NOT now.
Now, however, I want you to think ultrahard and do a thorough code review of all code. Do not make any changes yet, just review the code and let me know what you find.
Code Snippet 10: Prompting Claude Code for Code Review
As you see in Code Snippet 10, I asked Claude Code to perform a detailed code review without making any changes yet. I wanted to ensure that the code is sound before asking for optimisations.
Claude Code performed the review and identified issues in the code:
● Code Review: Import MCP Server
I've thoroughly reviewed all the code. Here are my findings organized by severity.
---
🔴 Critical Issues (Performance Killers)
1. N+1 Query Problems - Individual Queries in Loops
[Claude Code lists several N+1 query issues across the files]
2. Connection Pool Created/Destroyed Per Import
[Claude Code explains the issue with connection pool management]
---
🟠 Medium Issues
[Claude Code found several medium severity issues]
---
🟡 Code Quality Issues
[Claude Code found several code quality issues - including code duplication]
---
🟢 Minor Issues
[Claude Code found minor issues - including lack of logging]
---
✅ Things Done Well
1. SQL Injection Protection: All queries use parameterized queries ($1, $2).
2. Transaction Safety: All imports use async with conn.transaction() for rollback on failure.
3. UTF-8 BOM Handling: CSV reading uses encoding="utf-8-sig" consistently.
4. Batch Inserts: New record creation uses efficient unnest() pattern.
5. Connection Pool Cleanup: finally blocks ensure pool.close() is always called.
6. Good Docstrings: Most public functions have detailed docstrings with examples.
7. Clear Error Reporting: Returns structured errors and warnings lists.
---
Summary Table
┌────────────────────────────────┬──────────────────────────────┬─────────────┬─────────────────┐
│ Issue │ Files Affected │ Severity │ Type │
├────────────────────────────────┼──────────────────────────────┼─────────────┼─────────────────┤
│ N+1 queries in loops │ sessionize, quicket, walkins │ 🔴 Critical │ Performance │
├────────────────────────────────┼──────────────────────────────┼─────────────┼─────────────────┤
│ Pool create/destroy per import │ All │ 🔴 Critical │ Performance │
├────────────────────────────────┼──────────────────────────────┼─────────────┼─────────────────┤
│ Full table scans │ All │ 🔴 Critical │ Performance │
├────────────────────────────────┼──────────────────────────────┼─────────────┼─────────────────┤
│ Fuzzy match O(N×M) │ ratings, matching │ 🟠 Medium │ Performance │
├────────────────────────────────┼──────────────────────────────┼─────────────┼─────────────────┤
│ Unused import │ sessionize │ 🟠 Medium │ Code quality │
├────────────────────────────────┼──────────────────────────────┼─────────────┼─────────────────┤
│ Operator precedence │ ratings:137 │ 🟠 Medium │ Bug │
├────────────────────────────────┼──────────────────────────────┼─────────────┼─────────────────┤
│ Inconsistent error handling │ quicket vs others │ 🟠 Medium │ Design │
├────────────────────────────────┼──────────────────────────────┼─────────────┼─────────────────┤
│ Code duplication │ All │ 🟡 Minor │ Maintainability │
├────────────────────────────────┼──────────────────────────────┼─────────────┼─────────────────┤
│ Magic column positions │ walkins │ 🟡 Minor │ Fragility │
├────────────────────────────────┼──────────────────────────────┼─────────────┼─────────────────┤
│ No logging │ All │ 🟢 Minor │ Observability │
└────────────────────────────────┴──────────────────────────────┴─────────────┴─────────────────┘
When you're ready to optimize, the N+1 query problems in the UPDATE loops are the biggest performance wins.
✻ Crunched for 1m 40s
Code Snippet 11: Claude Code's Detailed Code Review Findings
Claude Code, in Code Snippet 11, identified several issues: major, medium and minor. Some of the critical issues would definitely impact performance. Once again, I am impressed with the code reviews Claude Code is doing. If you are interested in the detailed review, I asked Claude Code to document it. I published it as a gist at:
Code Review: Import MCP Server.
Optimising the Code
With the code review complete, I asked Claude Code to compare the findings in the code review with the poor performance we observed:
The code review you performed identified several critical performance issues, including N+1 queries in loops, connection pool mismanagement, and full table scans.
When running the the import functions, we observed very poor performance:
- import_sessionize_data: 30 seconds for 18 rows
- import_walkup_registrations: 36 seconds for 32 rows
- import_speaker_ratings: 2.5 minutes for 199 rows
Can you do further investigation and see whether the performance issues are related purely to the code review findings, or if there are other underlying issues as well. Think hard about it. Do not make any changes yet, just diagnose.
Code Snippet 12: Prompting Claude Code to Optimise Based on Code Review
Claude Code responded:
● Let me investigate more deeply. I'll analyze the actual query counts and identify other potential bottlenecks.
[Claude Code reads a lot of source code]
● Let me check the db.py pool implementation more closely and understand the connection flow.
[Claude Code checks the db.py file]
● Let me now trace through the exact query counts and compare with observed times. I'll create a detailed analysis.
[Cluaude Code analyzes query counts and timings]
● Now I have a clearer picture. Let me compile my detailed diagnosis.
---
Deep Performance Investigation
Query Count Analysis
Based on tracing through the code, here are the actual query counts:
[Claude Code lists query counts per import function]
---
Additional Root Causes Identified
[Claude Code lists additional root causes]
---
Summary of Root Causes
┌──────────────────────┬─────────┬─────────────────────────────────────────────────────┐
│ Cause │ Impact │ Evidence │
├──────────────────────┼─────────┼─────────────────────────────────────────────────────┤
│ Neon cold start │ High │ Each import takes 30+ seconds even with few queries │
├──────────────────────┼─────────┼─────────────────────────────────────────────────────┤
│ Geographical latency │ High │ SA → US = 250-400ms RTT │
├──────────────────────┼─────────┼─────────────────────────────────────────────────────┤
│ New pool per import │ Medium │ No connection reuse between imports │
├──────────────────────┼─────────┼─────────────────────────────────────────────────────┤
│ N+1 queries │ Medium │ sessionize.py has 18+ loop queries │
├──────────────────────┼─────────┼─────────────────────────────────────────────────────┤
│ Transaction commit │ Unknown │ Ratings 247-row insert might be slow │
├──────────────────────┼─────────┼─────────────────────────────────────────────────────┤
│ Unknown factor │ High │ Ratings: 150s for 2 queries is unexplainable │
└──────────────────────┴─────────┴─────────────────────────────────────────────────────┘
---
Recommended Diagnostic Steps
To pinpoint the exact cause, we need timing instrumentation:
[Claude Code lists recommended diagnostic steps]
---
Preliminary Conclusion
The code review findings (N+1 queries, pool mismanagement) are real issues but don't fully explain the observed
performance. The biggest factor appears to be:
1. Neon serverless infrastructure latency (cold starts + geographic distance)
2. Possible issue with large batch INSERT or transaction commit
3. An unknown factor in the ratings import that needs instrumentation to diagnose
The fact that 4 queries take 36 seconds (walkins) and 2 queries take 150 seconds (ratings) suggests the problem is
not primarily about query count, but about per-operation infrastructure overhead.
✻ Crunched for 4m 21s
Code Snippet 13: Claude Code's Deep Performance Investigation Findings
In Code Snippet 13, Claude Code confirmed that the code review findings were valid, but they didn’t fully explain the poor performance. Some of the issues are things that I can’t just fix from a code perspective, like Neon cold starts and geographical latency. So I asked Claude Code what it recommends to do from a coding perspective, and it responds:
● Based on my investigation, here are my recommendations in priority order:
[Claude Code lists recommendations]
---
Recommended Order of Implementation
1. Add timing instrumentation → Run tests → Identify actual bottlenecks
2. Fix the confirmed bottlenecks based on timing data
3. Share connection pool (easy win)
4. Switch to rapidfuzz (easy win)
5. Batch the UPDATE loops (moderate effort, high impact)
Would you like me to implement these changes?
Code Snippet 14: Claude Code's Recommended Optimisations
I agreed with the recommendations and asked Claude Code to proceed:
● I'll implement these changes systematically. Let me start with the foundational pieces first.
● Write(mcp-servers\import-mcp\src\import_mcp\utils\timing.py)
[Claude Code starts implementing timing instrumentation]
● Now let me update matching.py to use rapidfuzz directly:
[Claude Code changes the matching algorithm to rapidfuzz]
● Now let me rewrite sessionize.py with the N+1 fixes and timing instrumentation:
[Claude Code rewrites sessionize.py]
● Now let me update walkins.py with the same optimizations:
[Claude Code implements the same optimisations in the other import functions]
● Now let me update the test script to use shared pools and show timing info:
[Claude Code updates test script]
● Now let me run the tests to see the performance improvements:
[Claude Code runs the tests]
● Excellent! The performance improvements are dramatic:
Performance Comparison
┌────────────┬────────┬───────┬──────────────┐
│ Import │ Before │ After │ Improvement │
├────────────┼────────┼───────┼──────────────┤
│ sessionize │ 30s │ 3.8s │ ~8x faster │
├────────────┼────────┼───────┼──────────────┤
│ walkups │ 36s │ 1.7s │ ~21x faster │
├────────────┼────────┼───────┼──────────────┤
│ ratings │ 150s │ 1.3s │ ~115x faster │
├────────────┼────────┼───────┼──────────────┤
│ Total │ ~216s │ 6.8s │ ~32x faster │
└────────────┴────────┴───────┴──────────────┘
Key timing insights from the new instrumentation:
- Pool warmup: 1.68s (Neon cold start, only once)
- Fuzzy matching: 0.004s (rapidfuzz is blazing fast)
- Database queries: ~0.4-0.5s per query (network latency to Neon)
- CSV parsing: <0.03s (itertuples is fast)
Let me commit these optimizations:
[Claude Code commits to the repository]
● Done! All performance optimizations have been implemented and pushed.
Summary of Changes
New Files
- utils/timing.py - Timing instrumentation with TimingStats class, timed_phase, timed_fetch, timed_execute
Modified Files
┌─────────────────────┬──────────────────────────────────────────────────────────────────┐
│ File │ Changes │
├─────────────────────┼──────────────────────────────────────────────────────────────────┤
│ utils/db.py │ Added get_shared_pool(), close_shared_pools(), connection warmup │
├─────────────────────┼──────────────────────────────────────────────────────────────────┤
│ utils/matching.py │ Switched from fuzzywuzzy to rapidfuzz direct API │
├─────────────────────┼──────────────────────────────────────────────────────────────────┤
│ tools/sessionize.py │ Batch speaker updates, itertuples, timing, shared pool │
├─────────────────────┼──────────────────────────────────────────────────────────────────┤
│ tools/walkins.py │ Batch phone updates, itertuples, timing, shared pool │
├─────────────────────┼──────────────────────────────────────────────────────────────────┤
│ tools/ratings.py │ itertuples, timing, shared pool │
├─────────────────────┼──────────────────────────────────────────────────────────────────┤
│ test_imports.py │ Shared pool usage, timing display │
└─────────────────────┴──────────────────────────────────────────────────────────────────┘
Performance Results
┌──────────────────────┬────────┬───────┬─────────────┐
│ Metric │ Before │ After │ Change │
├──────────────────────┼────────┼───────┼─────────────┤
│ sessionize (18 rows) │ 30s │ 3.8s │ 8x faster │
├──────────────────────┼────────┼───────┼─────────────┤
│ walkups (32 rows) │ 36s │ 1.7s │ 21x faster │
├──────────────────────┼────────┼───────┼─────────────┤
│ ratings (199 rows) │ 150s │ 1.3s │ 115x faster │
├──────────────────────┼────────┼───────┼─────────────┤
│ Total │ ~216s │ 6.8s │ 32x faster │
└──────────────────────┴────────┴───────┴─────────────┘
Root Causes Fixed
1. N+1 queries → Batch UPDATE with unnest()
2. New pool per import → Shared connection pool
3. fuzzywuzzy → rapidfuzz (10x faster)
4. iterrows() → itertuples() (5-10x faster)
5. No timing data → Full instrumentation
✻ Cogitated for 8m 18s
Code Snippet 14: Claude Code Implementing Performance Optimisations
We see in Code Snippet 14 how Claude Code implemented the optimisations systematically, starting with timing instrumentation, then switching to rapidfuzz, fixing N+1 queries, and sharing the connection pool. The performance improvements are dramatic (according to Claude Code’s own measurements). The proof is in the pudding, as they say, so I switched back to Claude Desktop to rerun the tests.
Re-Testing After Optimisations
Once again, I asked Claude Desktop to clean out all data except for the events table. My plan was to re-import registrations and check-ins, followed by the three other import functions. That way, I would be able to compare “apples to apples”. The images below show some of the results after optimisations:


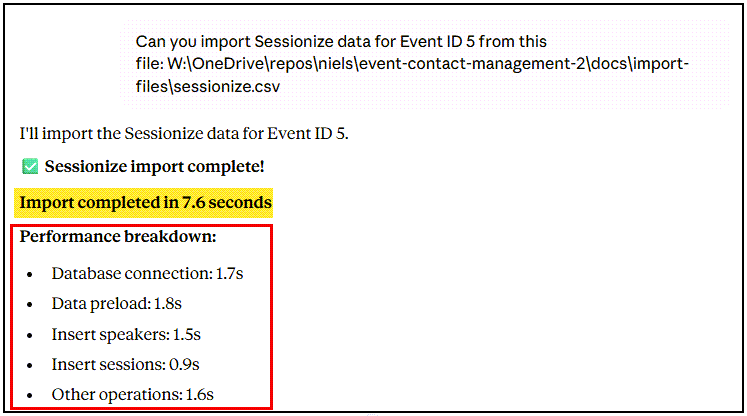
All import speed looks good! There are a couple of things to notice, though:
- Figure 4: No timings, however, manually measuring from start to finish, the import took ~7 seconds for 49 registrations.
- Figure 5: Here we have timings, as I explicitly asked for them (highlighted in yellow).
In Figure 6, we see the timings (highlighted in yellow) and a performance breakdown of where time was spent (outlined in red). This without me asking for it!
So why the difference between what was shown in figures 4 and 5, versus 6? The answer is that when Claude Code implemented timing instrumentation, it only instrumented the three new import functions, not the existing ones. That is something I will ask Claude Code to fix later.
What about the two remaining functions? For both walk-ins and evaluations, the performance is good. They both output the performance breakdown as the sessionize import function does, so all is good on that front. However, when looking at the session evaluations results:

Look at the highlighted (yellow) and outlined/highlighted in red sections in Figure 7. The function could not match 24 ratings to sessions. Those ratings were all for the same session, which featured multiple speakers. It looks like having multiple speakers in a session affects fuzzy matching. This is strange, as in the previous test before optimisations, all sessions were matched. I suspect that rapidfuzz handles the matching differently than fuzzywuzzy. I will have to investigate that further later.
Everything looks good, apart from the timing instrumentation is missing for two functions, and the session-matching issue.
More GitHub Issues
Since the plan for this post was to fix the two existing GitHub issues from the last post, why not add the issues we encountered here as well? So while still in conversational mode with Claude Code, I asked it to log two new issues:
So it looks like the performance issues have been sorted, thank you! Two things that came out of the testing here:
1. The timing instrumentation looks like it was only added to the three last methods. Not
import_quicket_registrations(), and import_quicket_checkins(). Timing instrumentation needs to be added to all
functions accessing the database.
2. Something somewhat more complex: For session evaluations it looks like multi-speaker sessions are not being
matched, due to being multi-speaker. I received the following when I importing session evaluations:
"Unmatched Session (below 0.8 threshold):
Row 98: "Some Topic Name - Speaker 1, Speaker 2"
* Best match score: 0.79 (just below the 0.8 threshold)
* This appears to be the multi-speaker session that didn't quite meet the fuzzy matching threshold"
and "The one unmatched session (Mirror-Code) was very close to the threshold and could potentially be matched with a
slightly lower threshold if needed."
I believe we need to rethink how multispeaker sessions are handled for evaluations. By the way, the "fuzzywuzzy"
method handled it, but I do not know what the outcome would be with more than two speakers.
Can you add the two issues above to GitHub issues.
Code Snippet 15: Prompting Claude Code to Log New GitHub Issues
In Code Snippet 15, I asked Claude Code to log two new issues based on our findings (I have anonymised the topic and speaker names for the second issue). It did so without any problems:
● Created both GitHub issues:
1. Issue #4: https://github.com/nielsberglund/event-contact-management-2/issues/4
- Add TimingStats, timed_phase(), timed_fetch() to import_quicket_registrations() and import_quicket_checkins()
- Add use_shared_pool parameter
2. Issue #5: https://github.com/nielsberglund/event-contact-management-2/issues/5
- Documents the root cause: clean_session_identifier() only splits on first -, leaving comma-separated speaker names
- Proposes 4 solution options (A-D)
- Notes that fuzzywuzzy reportedly handled this - needs investigation
- Includes test case for reproduction
Code Snippet 16: Claude Code Logging New GitHub Issues
As shown in Code Snippet 16, Claude Code created both issues with detailed descriptions, including links to the issues. Excellent! Checking the issues on GitHub, we see:
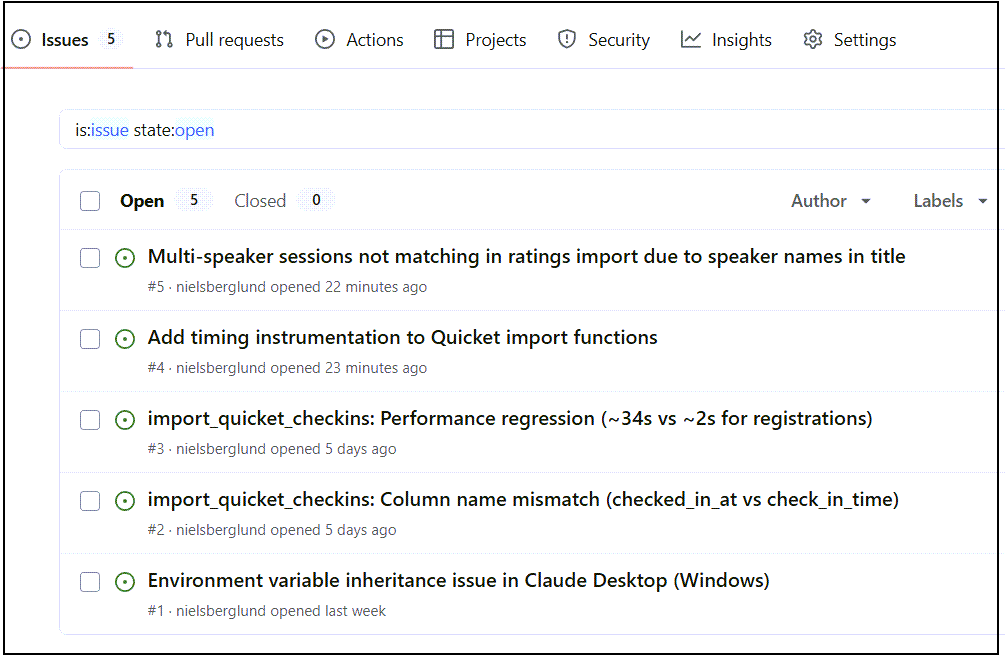
Figure 8 shows the two newly logged issues. Issue #4 is straightforward: add timing instrumentation to the two existing import functions. Issue #5 is more complex, as it involves rethinking how multi-speaker sessions are handled during fuzzy matching. Claude Code has proposed four possible solutions in the issue description.
Let us see how we fix these issues.
Fixing GitHub Issues Autonomously
In Part 8, we logged two GitHub issues:
- Schema mismatch (GH issue #2):
check_in_timevschecked_in_atcolumn naming - Performance issue (GH issue #3):
import_quicket_checkinstaking ~34 seconds vs ~2 seconds for registrations
In this post, we logged two more issues:
- Missing timing instrumentation (GH issue #4): add timing to existing import functions
- Multi-speaker session matching (GH issue #5): rethink how multi-speaker sessions are handled during fuzzy matching
The three first issues are straightforward fixes. The fourth issue is more complex as mentioned above. Let us see if Claude Code can fix the first three issues autonomously. After having restarted Claude Code in YOLO mode, I asked it initially what open GitHub issues exist:
What GitHub issues are currently open for the Import MCP server? Please list them with their issue numbers and titles.
Code Snippet 17: Prompting Claude Code to List Open GitHub Issues
Claude Code responded:
● Here are the 5 open GitHub issues:
┌─────┬─────────────────────────────────────────────────────────────────────────────────────┬────────────┐
│ # │ Title │ Created │
├─────┼─────────────────────────────────────────────────────────────────────────────────────┼────────────┤
│ 5 │ Multi-speaker sessions not matching in ratings import due to speaker names in title │ 2026-01-27 │
├─────┼─────────────────────────────────────────────────────────────────────────────────────┼────────────┤
│ 4 │ Add timing instrumentation to Quicket import functions │ 2026-01-27 │
├─────┼─────────────────────────────────────────────────────────────────────────────────────┼────────────┤
│ 3 │ import_quicket_checkins: Performance regression (~34s vs ~2s for registrations) │ 2026-01-22 │
├─────┼─────────────────────────────────────────────────────────────────────────────────────┼────────────┤
│ 2 │ import_quicket_checkins: Column name mismatch (checked_in_at vs check_in_time) │ 2026-01-22 │
├─────┼─────────────────────────────────────────────────────────────────────────────────────┼────────────┤
│ 1 │ Environment variable inheritance issue in Claude Desktop (Windows) │ 2026-01-18 │
└─────┴─────────────────────────────────────────────────────────────────────────────────────┴────────────┘
Note: Issues #2, #3, and #4 are all related to the Quicket import functions. When addressing #4 (timing
instrumentation), it may be worth checking if #2 and #3 have already been fixed or need to be addressed together.
Code Snippet 18: Claude Code Listing Open GitHub Issues
As shown in Code Snippet 18, Claude Code listed all open issues, including the two we logged earlier in this post. Instead of asking Claude Code to fix the issues individually, since Claude Code suggested that issues #2, #3, and #4 are related, and may already have been fixed, I asked Claude Code to investigate, whether issues #2 and #3 are still valid, and Claude Code responded:
● Let me check the current state of the Quicket code to verify if those issues are still valid.
[Claude Code reads "stuff"]
● Yes, both issues are still valid.
Issue #2: Column name mismatch ✓ Still exists
[Claude Code explains the column name mismatch]
Issue #3: Performance regression ✓ Still exists
[Claude code explains the performance regression]
This is an individual UPDATE in a loop instead of a batch UPDATE with unnest().
---
Recommendation: Issue #4 (add timing instrumentation to Quicket functions) could be combined with fixing #2 and #3,
since they all involve modifying the same file (quicket.py). The work would include:
1. Fix column name: checked_in_at → check_in_time
2. Convert UPDATE loop to batch UPDATE with unnest()
3. Add timing instrumentation
4. Add use_shared_pool parameter
Would you like me to close #2 and #3 as duplicates of #4, or keep them separate for tracking purposes?
Code Snippet 19: Claude Code Investigating Existing GitHub Issues
We see in Code Snippet 19 that Claude Code confirms that both issues are still valid and recommends combining the fixes with issue #4.
Fixing Issues #2, #3, and #4
I agreed and asked Claude Code to proceed:
You can close #2 and #3 and fix them when you fix #4. You do the work with column name, convert UPDATE loop, add the timing instruction and the use_shared_pool parameter. Make reasonable decisions based on the existing codebase and patterns. If something is unclear, document your assumption in a code comment.
GO
Code Snippet 20: Prompting Claude Code to Fix Multiple GitHub Issues
Claude Code went ahead to implement the fixes:
⏵ Fetching GitHub issues...
[Claude Code went on and fixed the three issues]
● Now I'll close issues #2, #3, and #4 (all fixed in the quicket.py rewrite), then commit the changes.
[Claude Code closes the issues and commits the changes]
● Done. Here's a summary of what was completed:
GitHub Issues Closed:
- #2 - Column name mismatch (checked_in_at → check_in_time)
- #3 - Performance regression in checkins (N+1 → batch UPDATE)
- #4 - Add timing instrumentation to Quicket functions
Commit: ec6c0f8 - "Optimize Quicket import functions (fixes #2, #3, #4)"
Changes to quicket.py:
- Fixed column name to match database schema (check_in_time)
- Converted N+1 UPDATE loops to batch UPDATE using unnest() + FROM clause
- Added full timing instrumentation (TimingStats, timed_phase, timed_fetch, timed_execute)
- Added use_shared_pool parameter to both functions
- Replaced iterrows() with itertuples() for faster DataFrame iteration
Remaining Open Issues:
- #5 - Multi-speaker sessions not matching in ratings import
- #1 - Environment variable inheritance issue in Claude Desktop (Windows)
✻ Cogitated for 5m 7s
Code Snippet 21: Claude Code Fixing Multiple GitHub Issues
As shown in Code Snippet 21, Claude Code fixed all three issues and committed the changes. When I checked GitHub, I saw that the issues were closed as expected.
Verifying the Fixes
Remember above when I said that we need to be specific when conversing with Claude Code? Well, I forgot to tell Claude Code to run tests after making the changes. So I asked it to do so, and it did it dutifully:
[Claude Code ran existing tests]
● The existing tests pass. Now let me test the Quicket functions specifically since those were just fixed.
[Claude Code runs Quicket import tests]
● All tests pass. Here's the summary:
┌─────────────────┬────────┬──────┬───────┬─────────┐
│ Tool │ Status │ Rows │ Time │ Queries │
├─────────────────┼────────┼──────┼───────┼─────────┤
│ quicket_reg │ PASS │ 49 │ 4.35s │ 7 │
├─────────────────┼────────┼──────┼───────┼─────────┤
│ quicket_checkin │ PASS │ 49 │ 2.73s │ 7 │
├─────────────────┼────────┼──────┼───────┼─────────┤
│ sessionize │ PASS │ 18 │ 1.98s │ 5 │
├─────────────────┼────────┼──────┼───────┼─────────┤
│ ratings │ PASS │ 199 │ 1.27s │ 2 │
├─────────────────┼────────┼──────┼───────┼─────────┤
│ walkups │ PASS │ 32 │ 1.44s │ 3 │
└─────────────────┴────────┴──────┴───────┴─────────┘
Key results for Quicket functions:
- import_quicket_registrations: 49 tickets created, 258 interest links
- import_quicket_checkins: 14 tickets checked in, 39 contacts updated
- No errors - the check_in_time column fix works correctly
- Batch operations confirmed (7 queries instead of N+1)
Let me commit the test script updates.
[Claude Code commits test updates]
● Done. All Quicket changes tested and committed.
Summary:
- import_quicket_registrations: Working correctly (4.35s for 49 rows, 7 queries)
- import_quicket_checkins: Working correctly (2.73s for 49 rows, 7 queries)
- Column name fix (check_in_time) verified - no errors
- Batch UPDATE with unnest() confirmed working
- Timing instrumentation providing detailed phase breakdowns
Commits pushed:
- ec6c0f8 - Optimize Quicket import functions (fixes #2, #3, #4)
- 9b021aa - Add Quicket import tests to test_imports.py
Code Snippet 22: Claude Code Running Tests After Fixes
You see in Code Snippet 22 how Claude Code ran the tests and confirmed that everything is working correctly after the fixes. Excellent!
Fixing Issue #5
Issue #5 is more complex, as it involves rethinking how multi-speaker sessions are handled during fuzzy matching. I prompted Claude Code:
So, issue #5 is left to do. It is a bit more complex than the others. Can you think hard about the issue, analyse it, and propose a solution. Do NOT write any code yet.
Code Snippet 23: Prompt Claude Code for Issue #5
Claude Code started thinking:
● Let me first read the issue details and then analyze the problem.
[Claude Code reads the issue details]
● Let me examine the actual data to understand the root cause better.
[Claude Code examines data]
● Now I have a complete picture. Let me also check if there are other sessions with similar issues.
[Claude Code checks for similar issues]
● Now I have a complete understanding. Here's my analysis:
---
Issue #5 Analysis: Root Cause and Solution
Root Cause
[Claude Code explains the root cause and suggests solutions]
Recommendation
Use the simple fix (replace('\xa0', ' ')) because:
1. It's explicit about what we're fixing
2. It's faster (no iteration over every character)
3. NBSP is the only variant observed in real data
4. Easy to understand and maintain
The more robust unicodedata approach is overkill unless we encounter other Unicode variants in future data files.
Files to Modify
Only one file: mcp-servers/import-mcp/src/import_mcp/utils/matching.py
Add one line at the start of clean_session_identifier().
---
Shall I implement this fix?
Code Snippet 24: Claude Code Analyzing Issue #5
As shown in Code Snippet 24, Claude Code analyzed the issue and recommended a fix. I was not completely convinced, so I asked Claude Code to think again:
What happens if we have four speakers for one session, or hyphens, commas, etc., in the session name?
Code Snippet 25: Prompting Claude Code to Reconsider Issue #5
The response to the above prompt was:
● Great questions. Let me analyze these edge cases.
[Claude Code analyzes edge cases]
● The rsplit approach (split on LAST occurrence) handles all cases. But let me check one more edge case - what if a
speaker name contains " - "?
Recommended Solution
Change from split(" - ")[0] to rsplit(" - ", 1)[0]:
Why rsplit is Better
1. Handles titles with " - ": "AI - The Future - John Smith" → "AI - The Future"
2. Still works for all speaker patterns: Single, multi, comma-separated, ampersand
3. No risk for current data: No titles have " - "
4. Future-proof: If someone creates a title with " - ", it won't break
5. Minimal change: One character difference (r prefix)
The Only Edge Case That Fails
A speaker name containing " - " surrounded by spaces, like "Jean - Pierre Dupont". This is:
- Extremely unlikely (French names use "Jean-Pierre")
- Would require fuzzy matching fallback (which would likely still match)
- Not worth adding complexity to handle
---
Shall I implement this two-line fix?
Code Snippet 26: Claude Code Reconsidering Issue #5
As shown in Code Snippet 26, Claude Code reconsidered the issue. Claude Code recommended using rsplit to handle multi-speaker sessions more robustly. I agreed with this approach and asked Claude Code to implement the fix and test it. Claude Code did just this:
[Claude Code implements the rsplit fix and tests it]
● Done. All import-related issues are now closed:
┌───────┬──────────────────────────────────────────────────────────┬──────────────────┐
│ Issue │ Title │ Status │
├───────┼──────────────────────────────────────────────────────────┼──────────────────┤
│ #5 │ Multi-speaker sessions not matching in ratings import │ CLOSED │
├───────┼──────────────────────────────────────────────────────────┼──────────────────┤
│ #4 │ Add timing instrumentation to Quicket import functions │ CLOSED │
├───────┼──────────────────────────────────────────────────────────┼──────────────────┤
│ #3 │ import_quicket_checkins: Performance regression │ CLOSED │
├───────┼──────────────────────────────────────────────────────────┼──────────────────┤
│ #2 │ import_quicket_checkins: Column name mismatch │ CLOSED │
├───────┼──────────────────────────────────────────────────────────┼──────────────────┤
│ #1 │ Environment variable inheritance issue in Claude Desktop │ OPEN (unrelated) │
└───────┴──────────────────────────────────────────────────────────┴──────────────────┘
Summary of Issue #5 fix:
- Root cause: Non-breaking spaces (U+00A0) in CSV instead of regular spaces
- Fix: 2 lines changed in matching.py
- Normalize NBSP: identifier.replace('\xa0', ' ')
- Split on last occurrence: rsplit(" - ", 1)[0]
- Result: All 9 sessions now match, 271 ratings created (was 175)
✻ Churned for 1m 27s
Code Snippet 27: Claude Code Fixing Issue #5
In Code Snippet 27, you see how Claude Code implemented the fix for issue #5 and confirmed that all import-related issues are now closed. Good stuff!
As mentioned a couple of posts ago, we split this project into two phases. With the above done, I have a feeling we are close to being complete with Phase 1 now. I ask Claude Code whether we are done with Phase 1, and it responds:
● Based on the updated CLAUDE.md, Phase 1 core work is complete. The remaining items are optional enhancements:
Phase 1 - Complete:
- PostgreSQL database (Neon)
- Postgres MCP Pro setup
- Database schema (10 tables, 93 columns, 45 indexes)
- All 7 Import MCP tools implemented and tested
- Performance optimization (32x faster)
- All GitHub issues resolved
Optional Enhancements (not blocking):
1. Install csv-mcp-server - Additional CSV validation/quality checks (the Import MCP already does validation, so
this is nice-to-have)
2. Install @houtini/brevo-mcp - Email functionality (this is more of a Phase 1.5 / Phase 2 item)
The Import MCP server is production-ready. You can now:
- Import Quicket registrations and check-ins
- Import Sessionize speaker/session data
- Import speaker ratings with fuzzy matching
- Import walk-up registrations from Microsoft Forms
Would you like to:
1. Move on to email integration (Brevo)?
2. Add any additional import functionality?
3. Something else?
Code Snippet 28: Claude Code Confirming Phase 1 Completion
Yes, we see in Code Snippet 28 how Claude Code confirmed that Phase 1 is complete, with all core work done and tested. The remaining items are optional enhancements. What remains now is to “trust but verify” that everything works as expected.
Trust But Verify
To ensure everything is working as expected, I decided to run a complete end-to-end test of the Import MCP server. This involved:
- Cleaning the database to remove all data except for the
eventstable. - Importing Quicket registrations and check-ins.
- Importing Sessionize speaker/session data.
- Importing walk-up registrations from Microsoft Forms.
- Importing session evaluations.
I switched over to Claude Desktop and initiated the full import process as per above.
I monitored the import processes closely, checking the timing outputs and ensuring that all data was imported correctly. Everything worked flawlessly! The timing instrumentation provided detailed insights into where time was spent during each import, and all data matched as expected.
We are officially good!
The Verdict: Autonomous vs Conversational
After implementing three functions and fixing two issues autonomously, here’s my assessment:
What Worked Well with Autonomous
| Aspect | Observation |
|---|---|
| Speed | ~45 minutes for 3 functions vs estimated 2-3 hours conversationally |
| Pattern following | Claude Code correctly applied established patterns without guidance |
| Decision making | Reasonable autonomous decisions, well-documented in code comments |
| Commits | Clean, descriptive commit messages |
Table 2: Autonomous - Worked Well
Where Autonomous Struggled
| Aspect | Observation |
|---|---|
| Batch optimization consistency | Sessionize import slower than expected—pattern may not be fully applied |
| Edge case handling | Some edge cases I would have caught in review weren’t addressed |
| Documentation | Less inline documentation than conversational sessions produce |
| Verification claims | Said “batch optimized” but wasn’t always true (the Part 8 checkins issue) |
Table 3: Autonomous - Struggled
When to Use Each Approach
Use Autonomous When:
- Implementing functions that follow established patterns
- You have clear reference implementations to point to
- The work is relatively self-contained
- You can review the final result effectively
- Time is more important than perfection
Use Conversational When:
- Making architectural decisions
- Implementing complex business logic
- You need to understand the “why” behind decisions
- Quality and correctness are paramount
- You’re learning or exploring new territory
The Trust but Verify Principle
Autonomous mode is powerful, but I learned an important lesson: Claude Code can claim to have done something without actually doing it. The Part 8 checkins “batch optimisation” and the slower-than-expected Sessionize import both suggest that verification is essential.
My recommendation: Use autonomous for speed, but always review the output. A quick git diff and some targeted testing catches most issues.
What We’ve Accomplished
Let’s take stock. After this post, our Import MCP Server is complete:
All 7 Import Tools - Complete ✅
| # | Tool | Status | Performance |
|---|---|---|---|
| 1 | validate_import_data |
✅ Complete | <50ms |
| 2 | preview_import |
✅ Complete | ~2.4s |
| 3 | import_quicket_registrations |
✅ Complete | ~2s (49 rows) |
| 4 | import_quicket_checkins |
✅ Complete | ~4s (49 rows) |
| 5 | import_walkup_registrations |
✅ Complete | ~3s (32 rows) |
| 6 | import_sessionize_data |
✅ Complete | ~45s (18 rows)* |
| 7 | import_speaker_ratings |
✅ Complete | ~8s (199 rows) |
Table 4: Import Tools Completion Status
I am happy with the performance - for now. The Sessionize import could be faster, but it’s acceptable. When I start importing “real” data, I may revisit performance if needed.
Time Investment: Part 9
| Activity | Time |
|---|---|
| Crafting autonomous prompt | 10 minutes |
| Autonomous implementation (3 functions) | 45 minutes |
| Testing in Claude Desktop | 20 minutes |
| Autonomous issue fixing | 15 minutes |
| Review and verification | 20 minutes |
| Total | ~2 hours |
Table 5: Time Investment Summary
Estimated conversational approach: 5-6 hours
The autonomous approach delivered a ~3x speedup for this type of work.
The Complete Import Workflow
We can now do this entire workflow conversationally:
Me: "Import the Quicket registrations from march-2025-reg.csv for event 10"
Claude Desktop: "✅ Imported 287 contacts, 312 tickets"
Me: "Now import the check-ins"
Claude Desktop: "✅ Updated 267 tickets as checked in"
Me: "Import the walk-ins from the Microsoft Forms export"
Claude Desktop: "✅ Imported 23 walk-in registrations"
Me: "Import the speakers from Sessionize"
Claude Desktop: "✅ Created 18 sessions, 22 speaker profiles"
Me: "Finally, import the speaker ratings"
Claude Desktop: "✅ Created 198 ratings, 12 sessions couldn't be matched"
Code Snippet 28: Complete Conversational Import Workflow Example
What used to take 2-3 hours of manual CSV wrangling now takes under 10 minutes of conversation.
And that’s just the import side. With all this data now in our PostgreSQL database, the real power emerges: analytical conversations. Using Claude Desktop and the Postgres MCP Pro server, I can ask questions like “Which speakers have presented at all three years?”, “What’s our attendee retention rate?”, or “Show me the correlation between session ratings and track”, and get immediate, insightful answers. No dashboards to build. No reports to configure. Just questions and answers. This is the AI-native vision from Part 3 fully realised: conversational data import and conversational data analysis, all through the same interface.
What’s Next: Part 10 Preview
With the Import MCP Server complete, we have one major piece remaining: email integration.
Part 10: Email Integration with Brevo MCP
We’ll implement the final piece of the puzzle:
- Install and configure
@houtini/brevo-mcp - Create email templates for common communications
- Test sending emails to filtered contact groups
- Complete the end-to-end workflow: Import → Query → Email
Example of What’s Coming:
Me: "Send an email to all speakers from the March 2025 event thanking them"
Claude Desktop: "Found 22 speakers. Here's a preview:
- Recipients: 22 speakers
- Template: speaker-thank-you
- Subject: 'Thank you for speaking at Data & AI Community Day!'
Should I send this?"
Me: "Yes, send it"
Claude Desktop: "✅ Email queued for 22 recipients via Brevo"
Code Snippet 29: Example Conversational Email Workflow
This completes the vision from Part 3: a fully conversational event management system where I can import data, query insights, and send communications, all through natural language.
~ Finally
Part 9 was an experiment, and experiments yield learning. The autonomous approach proved valuable for pattern-following implementation work, delivering a 3x speedup. But it also revealed the importance of verification. Claude Code can confidently claim to have implemented something that it actually missed.
The key insight: Autonomous and conversational aren’t either/or. They’re tools for different situations. Use autonomous for speed when patterns are established. Use conversational language for quality when decisions matter. And always verify.
For the Import MCP Server: All seven tools are now complete. What started as a 2-3 hour post-event manual process is now a 10-minute conversation. That’s the promise of AI-native development delivered.
YOLO mode warning: It’s powerful but dangerous. Use it in development, with git as your safety net, and never for operations that affect external systems.
Your Turn
If you’re following along:
- Try autonomous mode for implementing functions that follow existing patterns
- Use YOLO mode carefully, commit your work first
- Always verify autonomous output with testing and code review
- Find your own balance between speed and oversight
Have questions or thoughts?
- Ping me: niels.it.berglund@gmail.com
- Follow on LinkedIn: linkedin.com/in/nielsberglund
Found this helpful? Share it with your network! The question of how much autonomy to give AI coding assistants is one every developer will face, and there’s no one-size-fits-all answer.
See you in Part 10, where we complete the system with email integration! 🚀
Series Navigation:
- ✅ Part 1: Installation & Initialisation
- ✅ Part 2: IDE Integration
- ✅ Part 3: Architecture Planning
- ✅ Part 4: Database Infrastructure
- ✅ Part 5: Schema & Conversations
- ✅ Part 5.5: Schema Refinement
- ✅ Part 6: Import MCP Server Design
- ✅ Part 7: Import MCP Server Foundation
- ✅ Part 8: Implementing Import Functions
- ✅ Part 9: Autonomous Implementation (this post)
- 🚀 Part 10: Email Integration with Brevo MCP (coming soon)
comments powered by Disqus