This is the 18:th post in a series about Microsoft SQL Server R Services, and the 17:th post that drills down into the internal of how it works. To see other posts (including this) in the series, go to SQL Server R Services.
The last Internals posts have discussed the transport of data between SQL Server and the SqlSatellite. In Internals - XVI we looked at how data came back from the SqlSatellite, and what the data looked like.
This post is a continuation of that post, and here we’ll look at what happens inside SQL Server when data is returned from the SqlSatellite and the R engine.
Recap
In Internals - XVI we looked at the packets being sent back to SQL Server from the SqlSatellite when a dataset is returned. We saw how there were actually two packets coming back, one small and one bigger, we deduced that those packets were:
- The smaller packet had something to do with column meta-data. We’ll try and see what we can find out about this packet in this post.
- The bigger packet held the actual data.
The reason why the second package was bigger was due to the data being treated as originating from nullable columns, so quite an overhead was put onto the various columns:
| Data Type | 1 Row | 2 Rows | Comment |
|---|---|---|---|
| tinyint | 2051 | 2055 | - |
| smallint | 2051 | 2055 | - |
| int | 2051 | 2055 | - |
| real | 1078 | 1086 | - |
| float | 1078 | 1086 | No difference related to storage size |
| bigint | 1078 | 1086 | |
| money | 1078 | 1086 | |
| decimal | 1078 | 1086 | No difference related to storage size |
Table 1: Packet Sizes from SqlSatellite
Part of the overhead is the 32 bytes column overhead as we discussed in Internals - XIV, and a 28 bytes end-sequence, where the end-sequence appears once per data-set, and is not per column. It is somewhat like a row in the data-set. Part of this post is trying to figure out what goes on with this end-sequence.
When looking at the various sizes coming back, we see it is a lot less than what we saw in Internals - XIV, sending data to SqlSatellite. This is due to R supporting a lot less data-types than SQL Server, and therefore the data might be implicitly converted to a compatible data type.
Housekeeping
Housekeeping in this context is talking about the tools we’ll use, as well as the code. This section is here here for those of who want to follow along in what we’re doing in the posts.
Helper Tools
To help us figure out the things we want, we will use Process Monitor, and WinDbg:
- Process Monitor, will be used it to filter TCP traffic. If you want to refresh your memory about how to do it, we covered that in Internals - X as well as in Internals - XIV.
- In the last few posts I have used WinDbg preview a my debugger, but in this post I am reverting back to WinDbg “classic”. If you need help with setting it up, that is covered in Internals - I.
Code
The code below sets up the database and creates some tables with some data. It is more or less the same as we’ve used in the last posts:
|
|
Code Snippet 1: Database, and Database Object Creation
The code we’ll use should by now look very familiar:
|
|
Code Snippet 2: Base Code to Execute
The reason there is a Sys.sleep in the code in Code Snippet 2, is so we can more easily determine at about what time data should be coming back from the SqlSatellite.
WinDbg Debugging
In Internals - XV, we used WinDbg, and we saw the routines involved when sending data to the SqlSatellite:
|
|
Code Snippet 3: Routines Used when Sending Data
Now we’ll aim to do the same thing here, and we’ll start with trying to find routines being used when receiving data, and we’ll start with trying to find the “main” routine for receiving results. Remember in
Internals - XV, we saw how sqllang!CUDXR_ExternalScript::PushRow where were things “started”, when sending data. Perhaps there is something similar in the CUDXR_ExternalScript when receiving? So:
- Start up WinDbg as admin.
- Attach to the SQL Server process.
After having attached to the process, execute in the WinDbg console: x sqllang!CUDXR_ExternalScript*. That returns quite a few routines, from which we can see if anyone looks promising. When I ran it I found a couple that caught my interest:
|
|
Code Snippet 4: Interesting sqllang!CUDXR_ExternalScript Routines
Let’s now set breakpoints at the two routines above, plus a breakpoint at sqllang!CSatelliteCargoContext::SendPackets. The reason for the breakpoint at SendPackets is that it is there to indicate where we are, as PullRow can be called based on processing inside SQL Server, not only as result of data coming back from the SqlSatellite. Now execute the code in Code Snippet 2, and you’ll see how:
PullRowis called once beforeSendPackets- that’s not interesting to us.SendPacketsis called.PullRowis called.- A pause followed by
ProcessResultRowsbeing called twice.
A couple of questions comes up after having seen the above:
- Why is the second
PullRowcalled immediately afterSendPackets? - Why are there two
ProcessResultRows, when only one row is returned?
Just to confirm the last bullet point; change the TOP clause in Code Snippet 2 to 5 instead of one and execute again. The breakpoint at ProcessResultRows is now hit 6 times. So ProcessResultRows is definitely related to number of rows returned, but also something else. Let’s see if we can figure out what happens here:
- Disable all breakpoints except for the
ProcessResultRowsbreakpoint. - Clear the WinDbg command window by
.cls. - Change the
TOPclause in Code Snippet 2 to be 3. - Execute the code.
- Each time the
ProcessResultRowsbreakpoint do awt -l4(trace and watch 4 levels deep). - After each “trace and watch”, copy the output to new files and name them
wt1.txt,wt2.txt, etc.
There should, after completing the execution, be four files, let’s compare these four files.
NOTE: If you haven’t done the
wtas above, you can download the four files, plus a couple of others from here.
What we see is that the first file is bigger than the others, it has ~165 lines whereas the others are between 65 - 70 lines. The last third part of the first file (from about line 104), looks very much like the second and third files. We can also see that the fourth file is not similar to the other tree.
Now what we’ll do is to look at the similarities between the three first files and try to understand what is happening. In the files we see some interesting routines:
|
|
Code Snippet 5: Routines from sqllang!CUDXR_ExternalScript::ProcessResultRows
By now we understand that ProcessResultRows is doing what it says on the packet; it takes the rows coming back from the SqlSatellite, processes it, and then outputs it through sqllang!CUDXR_ExternalScript::OutputRow. From what we see in Code Snippet 5, it looks like the rows being outputted is outputted in the TDS format - look at the calls to sqllang!CTds74::SendRowImpl. This would make sense since clients etc., do not “speak” BXL, and from what we’ve seen - BXL is what is coming back from the SqlSatellite.
EDITED: The following section down to
PullRowhas been slightly changed, to make it more readable.
So the similar code in the three files (wt1, wt2, and wt3) processes the rows coming back, and outputs them as TDS, cool! So what about the first part of the first ProcessResultRows, what does that do? Let’s have a look at the trace file for the first ProcessResultRows:
|
|
Code Snippet 6: Routines from First ProcessResultRows
In Code Snippet 6 we see various parts of the first 2/3 of the first call to ProcessResultRows. What is interesting is the sqllang!CServerCargoContext::ReceiveOneDataChunk, sqllang!CSQLSatelliteMessageDataChunk::ReadPayloadHeader and the sqllang!CSQLSatelliteCommunication::SendAckMessage calls.
From what I gather, the ReceiveOneDataChunk routine reads in data that has been received from a socket, the ReadPayloadHeader reads the column header for each column in the result-set being returned, in order to determine data types etc. The SendAckMessage, sends a message back to the SqlSatellite, most likely indicating that SQL Server has received the two packages being sent from the SqlSatellite. We can confirm the “sending message back” part by:
- Disabling all break-point in WinDbg except for the breakpoint at
sqllang!CUDXR_ExternalScript::ProcessResultRows. - Set a breakpoint at
sqllang!CSQLSatelliteConnection::WriteMessage, but disable it. - Run Process Monitor as admin and load the filter we used in
Internals - XVI where we filtered for
TCP SendandTCP ReceiveforBxlServer.exe.
Execute the code in Code Snippet 2, and when you hit the ProcessResultRows breakpoint, look at the output from Process Monitor. You should see something like so:
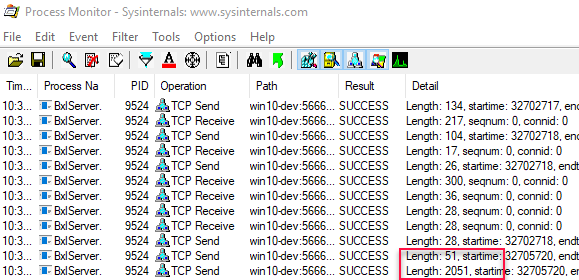
Figure 1: Output Before WriteMessage
We see in Figure 1 how the two data packets have been sent to SQL Server, but nothing else has happened. Enable the WriteMessage break-point and continue the execution. We’ll now break at WriteMessage, but nothing has happened in Process Monitor (no more packages have been sent or received). However, when we now continue the execution we’ll see in *Process Monitor how a packet is sent to the SqlSatellite (BxlServer.exe) with a length of 28 bytes, and then two packets are returned back from the SQlSatellite:
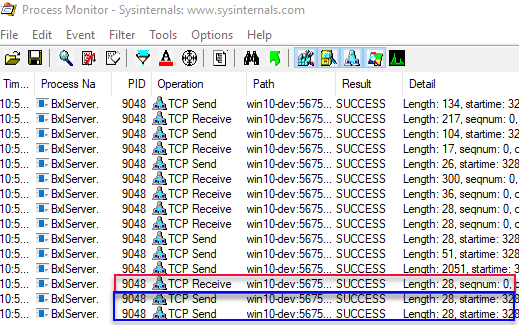
Figure 2 Output After WriteMessage
We see the ack message sent to the SqlSatellite outlined in red in Figure 2, and the two packets coming back outlined in blue. Further down in this post as well as in an upcoming post we’ll see if we can determine what the two packets coming back from the SqlSatellite do.
Now we’ve seen how the first ProcessResultRows is doing both schema “stuff” as well as processing the first row, and how the second and third ProcessResultRows, handle the remaining rows. What about the fourth file, the last ProcessResultRows - what does that one do? Let’s have a look at some of the calls that happens:
|
|
Code Snippet 7: Routines from Last ProcessResultRows
From the code in Code Snippet 7 we see how there is a ReceiveOneDataChunk call, which indicates data is being read after having been received from a socket. It also looks like that this last ProcessResultRows indicates that there are no more data: sqllang!CUDXR_ExternalScript::EndOutput, sqllang!CTdsConn<0>::EndResultSetImpl and sqllang!SendDoneWarnings. The question is what indicates this in the packets SQL Server receives from the SqlSatellite? This is now some speculation from my side, but I strongly suspect this originates from one of the 28 byte packets coming back from SqlSatellite after SQL Server sent the ack message above. I also think that the end-sequence that we mentioned in
Internals - XVI as well as in the Recap above, has something to do with this.
Now we should be able to answer the question above about why there are one more ProcessResultRows than rows returned, and we should also have a fairly good grasp of what happens when processing rows returned from the SqlSatellite:
- Rows are processed by
sqllang!CUDXR_ExternalScript::ProcessResultRows. - During the first
ProcessResultRowsthe column header(s) are processed, followed by the first row. - Subsequent rows are processed by
ProcessResultRows. - A final
ProcessResultRowsprocesses one of the packets received back from SqlSatellite after ack message has been sent.
So, what about the first question we had above; why is there a PullRow called straight after SendPackets, e.g. the PullRow happens before data is returned from the SqlSatellite? To try to figure this out, let’s disable all breakpoints, except for the breakpoint at sqllang!CUDXR_ExternalScript::ProcessResultRows, and execute Code Snippet 2 again (you can take out the Sys.sleep if you want). When you execute and hit the breakpoint ProcessResultRows for the first time, look at the call-stack: k:
|
|
Code Snippet 8: Call Stack at First ProcessResultRows
What we see in Code Snippet 8 is the important part of the call-stack and we can see how ProcessResultRows is called from within PullRow. Interesting, PullRow is called right after SendPackets, before the result has come back, and still ProcessResultRows is called from within PullRow, after the result is back? Let’s see if we can figure out what’s happening:
- Disable all breakpoints.
- Set a breakpoint at
sqllang!CUDXR_ExternalScript::PullRow. - Change the
Sys.sleep(10)in Code Snippet 2, toSys.sleep(60). - Execute the code.
- Continue past the first
PullRow.
When you hit the PullRow for the second time, do a wt. You’ll see how the code continues, up until the execution starts in the R engine, and the code hits Sys.sleep. At this stage, copy out the output from wt into a new file (call it pull_row_1.txt).
NOTE: The trace files for
PullRoware also part of the download mentioned above.
At some stage the execution continues, and after the full wt, copy the whole trace into a second file pull_row_full.txt. Now open the pull_row_1.txt file, and look at the last 11 lines (for me it starts at around line 888):
|
|
Code Snippet 9: Call Stack at End of First PullRow
It seems from the code in Code Snippet 9, that we wait to be signaled, so the execution can continue, and when we open the “full” file (pull_row_full.txt), we can see that, that is indeed what happens:
|
|
Code Snippet 10: PullRow Being Signaled
From Code Snippet 10, we see how Pull is signaled, and continues on with a Switch and a TaskTransition. The signal happens when SQL Server receives data from the SqlSatellite. There is an internal method sqllang!CSQLSatelliteConnection::ReadCallBackInternal which is being called when data is received, and part of ReadCallBackInternal is a signal call sqllang!EventInternal<SuspendQueueSLock>::SignalAll.
Having briefly discussed signaling, let’s go back to pull_row_full.txt and look further down in the file, where we see our first ProcessResultRows:
|
|
Code Snippet 11: ProcessResultRows Called in PullRow
We see how the code in Code Snippet 11 is the same as the first lines of the file wt1.txt.
Now we should be able to answer the first question we had; why PullRow is called directly after SendPackets: it is being called to wait for a call-back and continue handling receiving of data. But what else goes on in PullRow, we see the first ProcessResultRows at around line 3342, so there must be other “stuff” happening as well?
In fact, if we look a couple of lines above where we found ProcessResultRows in pull_row_full.txt we’ll see something like so:
|
|
Code Snippet 12: End of ProcessOutputSchema
What we see in Code Snippet 12 is how, above the first call to ProcessResultRows, we are in a routine named ProcessOutputSchema, and if we go upwards we see how there are at least three more routines dealing with schema:
sqllang!CUDXR_ExternalScript::GetOutputSchemasqllang!CServerCargoContext::ReadSchemaInternalsqllang!CServerCargoContext::ReadSchemaFromPackets
If we were to set breakpoints at those routines together with PullRow and ProcessResultRows, the flow (highly simplified) when executing would be something like this:
|
|
Code Snippet 13: Code Flow Handling Schema
So what SQL Server is doing is that before it start processing the returning rows, it determines what the schema is for the result-set. As far as I can tell, SQL Server uses both the initial “small” packet from the SqlSatellite as well as the packet containing the actual result-set data.
Summary
This post tried to determine what SQL Server is doing when data is being returned from the SqlSatellite. We saw how, after the data packet(s) were sent to the SqlSatellite:
- Immediately
sqllang!CUDXR_ExternalScript::PullRowwas called, and waited to be signaled when data was returned. - The schema of the returning data was determined by calls to
sqllang!CUDXR_ExternalScript::ProcessOutputSchema,sqllang!CUDXR_ExternalScript::GetOutputSchema,sqllang!CServerCargoContext::ReadSchemaInternal, andsqllang!CServerCargoContext::ReadSchemaFromPacket. - The result rows were processed, and turned into TDS packets, by calls to
ProcessResultRows(oneProcessResultRowsper row). - A final
ProcessResultRowswas called to indicate that no more rows are coming.
The figure below illustrates the flow:
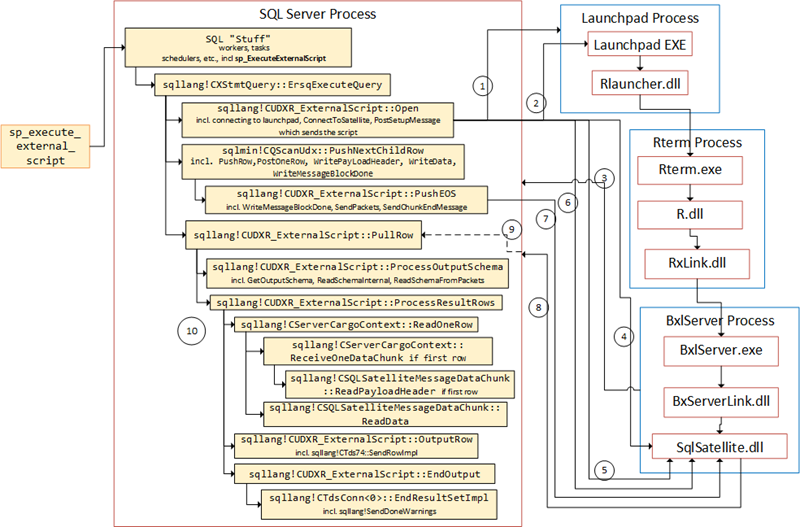
Figure 3: Code Flow Receiving Data from SqlSatellite
If you have read Internals - XV, you see how Figure 3 is similar. I have however “compacted” the sending data to SqlSatellite somewhat. The numbered arrows shows the communication out to and in from SQL Server, and in what order it happens:
- SQL Server opens named pipe connection to the launchpad service.
- Message sent to the launchpad service.
- After the call above, the SqlSatellite opens a TCP/IP connection to SQL Server.
- SQL Server sends the first packet to the SQL Satellite for authentication purposes.
- A second authentication packet is sent to SqlSatellite.
- The script is sent from inside
sqllang!CSatelliteProxy::PostSetupMessage - The data for
@input_data_1is sent together with two end packets. - Packet are coming back to SQL Server containing meta-data and the actual data.
PullRowis being signaled.- Execution continues to process meta-data as well as result rows.
There are still a couple of things to discuss about data coming back to SQL Server, as well a how errors are handled, and we’ll do that in a future post.
~ Finally
If you have comments, questions etc., please comment on this post or ping me.