This is the sixth post in a series about Microsoft SQL Server R Services, and the fifth post that drills down into the internal of how it works. To see other posts (including this) in the series, go to SQL Server R Services.
In Internals - III and Internals - IV, we looked at how the launchpad service creates RTerm processes when we execute an external script.
The Internals - IV post came about due to an email from Bob Albright ( @bob_albright), pointing me to some resources (a blog-post) regarding the processes the launchpad service creates.
In his email Bob also, kindly enough, attached some code. The code highlighted some behavior when creating the RTerm processes, especially around parallelism. In this blog-post we’ll follow up on that and look into the effect parallelism has on process creation.
Recap
In Internals - IV, we saw how:
- The launchpad service creates by default 6 RTerm processes when an external script is executed by a user. One of the processes will be used for the execution of the script and torn down afterwards. The other 5 is added to the process pool. In essence the launchpad service creates 5 + 1.
- If more (or less) processes than 5 is needed, a setting
PROCESS_POOL_SQLSATELLITE_GROWTHcan be set inrlauncher.config. The value of the setting defines number of processes to create (as with default it will be setting value + 1). - When a user executes subsequent requests, or concurrent requests from different sessions, processes are picked up and used from the pool.
- The launchpad service simultaneously creates a new process.
Previously I had the assumption that “somehow” the number of processes created had to be configurable, and that the reason for creating multiple processes has to do with performance.
In the post we verified that, and this was much due to the
blog-post Bob pointed to in his - previously mentioned - email. That particular post also briefly mentioned MAXDOP, and what to think about in terms of pool size. That and Bob’s code lead to this blog-post.
Code
Before diving into the “stuff”, let’s look at the code we’ll use. The code we have used in previous posts has been very, very minimal. Today we’ll be “very advanced” and select data from a table in a database - talk about cutting edge!! What we want to do is to execute some linear regression functions against data, and see what happens in different scenarios.
In Code Snippet 1 below, we set up the database and a table with some data we can use, all in all 30 million records:
|
|
Code Snippet 1: Setup of Database, Table and Data
The data is completely “useless”, but it can at least be used for analysis work, it looks something like so (just a few rows):
!{}(/images/posts/sql_r_services_random_data.png)
Figure 1: 10 Rows Random Data
What we want to do with the data is to create a linear regression model over it, where - ultimately - we want to predict the value of y, and we believe y is related to rand1, rand2, rand3, rand4 and rand5. In our examples we are not really interested in y, but we want to see what the intercept value(s) is. If we used open source R (CRAN R), the code for this would look something like so:
|
|
Code Snippet 2: Linear Regression Using CRAN R
Seeing that this is about SQL Server R Services, we should be using the equivalent RevoScaleR function: rxLinMod: r <- rxLinMod(y ~ rand1 + rand2 + rand3 + rand4 + rand5, data=<some input data>);, and we would execute it from sp_execute_external_script:
|
|
Code Snippet 3: Linear Regression in SQL Server
So the code in Code Snippet 3 is what we will “play” around with in this post. Some comments:
- First line of the script (the
@scriptparameter) is commented out;Sys.sleep(30). We’ll use it at one stage to be able to look a little bit closer at what is happening. - As we did in Internals - IV we grab the process id of the RTerm process the code executes under.
- In the
OutputDataSetvariable we output a data-frame consisting of the process id, how many rows we processed and the intercept value. - The output data is being presented as a result set, by the
WITH RESULT SETS ...statement. - Oh, and for “giggles” we check how long the execution takes (first line and last line).
In addition to the code above, we’ll also use Process Explorer, to see how many processes are created as well as memory consumption etc. If you have read Internals - III and Internals - IV, you should be comfortable with Process Explorer.
Parallel Execution
So the blog-post is about what impact parallel processing will have on the process creation, but before we go down that “rabbit” hole, let’s see what it looks like during non-parallel execution:
- Restart the launchpad service (this is to clean-up any RTerm processes).
- Navigate to the
Launchpad.exeprocess in Process Explorer. - Execute the code in Code Snippet 2.
- While the code is executing, look in Process Explorer for RTerm processes.
In Process Explorer you should see something similar to this:
!{}(/images/posts/sql_r_services_lin_reg1.png)
Figure 1: Processes from Code Execution
What you see in Figure 1 matches pretty good with what we discussed in
Internals - III and
Internals - IV; while a single user executes sp_execute_external_script 6 RTerm processes are alive, and one of the processes is the process where the script executes under. In this case it was process id 10120, and we determined that from the CPU value (.32) as well as Private Bytes: 1,023,376 K and Working Set 189,268 K respectively. We can further confirm the process the code executed under by looking at the result coming back:
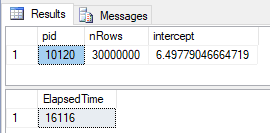
Figure 2: Result from Code Execution
From Figure 2 we can indeed see that the process id was 10120, and that we ran the regression model over 30 million rows. The time it took to execute the code was ~16 seconds. The query plan looks like in Figure 3:
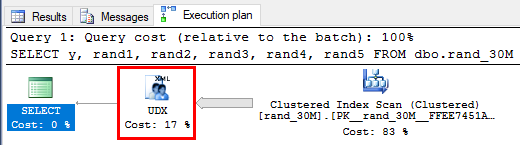
Figure 3: Actual Query Plan
In Figure 3 we see how we do clustered index scan for our rows and then hand it over to the UDX operator. The UDX operator comes normally in play when we do XML related processes, but - as we can see - it also comes into the picture for external scripts. It kind of makes sense as it is an Extended Operator.
This is all well and good, but it is not really anything new from what we discussed in Internals - III and IV.
So what about parallel execution? When you read documentation about SQL Server R Services it always mentions how efficient it is to execute external scripts as one can utilize SQL’s parallelism. How does this work then? In “normal” SQL Server parallelism, SQL Server decides whether to execute a statement in parallel or not, and the MAXDOP setting defines the number of processors the statement will execute on.
For SQL Server R Services it works in a similar way, except that you have to explicitly say that you want to execute in parallel. To specify parallel execution you use a parameter on the sp_execute_external_script procedure: @parallel. The parameter can either be either 0, no parallelism which is default, or 1.
NOTE: Even if you specify that you want to execute in parallel, SQL may choose not to do it.
So in order to enable parallelism, we need to add the parameter to the stored procedure, and in Code Snippet 4 below we have inserted the parameter right after @input_data1 parameter:
|
|
Code Snippet 4: Using the @parallel Parameter
So let’s see what impact the change we did in Code Snippet 4 has. For now we will not look at the RTerm processes, so you can just execute the code with the @parallel = 1 parameter set. On my machine which is a 4 core machine with hyper threading (i.e. 8 processors) and MAXDOP is set to 0 (use all processors), I get the following result when I execute:
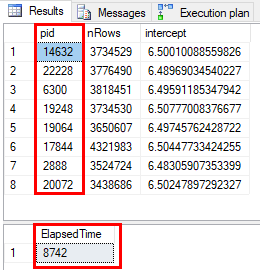
Figure 4: Result from Parallel Execution
In Figure 4 we see how the results are returned from 8 RTerm process id’s. This is to be expected when SQL uses parallelism and MAXDOP is 0. Oh, and BTW - according to people “in the know” you should not have MAXDOP set to 0 if you run on an HT box.
Here is an article about MAXDOP settings.
We also see from Figure 4 that we executed in ~8.7 seconds, roughly half the time it took when we didn’t use parallelism.
NOTE: There is no guarantee that you will improve performance by using parallelism, so it is a good idea to always test against the workloads you are using.
The query plan from the execution also shows parallelism:
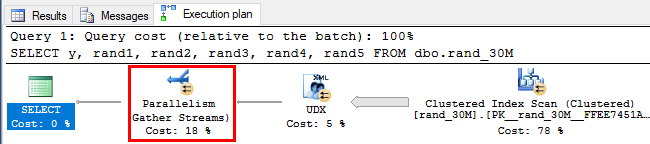
Figure 5: Query Plan With Parallelism
The interesting part with the query plan, as Bob pointed out to me, is that the UDX operator gets pushed before the Parallelism operator.
Let us now get back to what we started this with; how parallelism affects process creation. From what we have seen above, we can be fairly certain that 8 processes have been created, but let’s make sure that it really happens:
- Un-comment the line in the R script saying
Sys.sleep(30). We’ll use this pause to be able to closer see what happens. - Restart the launchpad service.
- Navigate to the
Launchpad.exeprocess in Process Explorer. - Execute the code.
- While the code executes look closely at the RTerm processes under the launchpad process in Process Explorer.
On my box the RTerm processes looks like so:
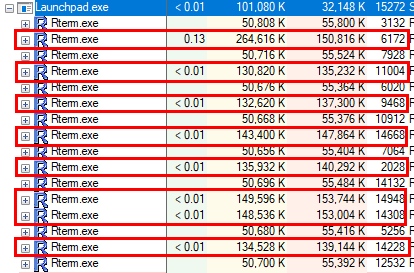
Figure 6: RTerm Processes and Parallelism*
From Figure 6 we can see how there are 8 executing processes (the outlined rows), and 16 processes altogether. So when executing in parallel, the launchpad service creates two processes for each task, where one of the two processes are used for execution of the R code, and the other is being added to the process pool. The processes that are being used to executed on, are torn down after execution - and left are the ones in the process pool.
However if the level of parallelism (tasks) are less than the number of processes to be created, (5 by default or the value of PROCESS_POOL_SQLSATELLITE_GROWTH), then the launchpad service creates as many process as required so that there always is the required number of processes in the pool.
An example of this is if PROCESS_POOL_SQLSATELLITE_GROWTH has not been set, and we are working with 5 as default; if the level of parallelism is 4, then 9 processes will be created - 4 for execution, and 5 for the pool.
So why would the level of parallelism be less than the required number of processes? Well, we may execute on a box with few processors, maybe not so likely, or MAXDOP is set (see below).
CRAN R Functions
So far we have used RevoScaleR functions in our script code, what happens if we want to use a CRAN R function instead. Something similar to what is in Code Snippet 2? That works fine as well, multiple RTerm processes will process the data. I will not show the code here, but you can easily try it our yourselves.
Max Degree of Parallelism (MAXDOP)
So MAXDOP is a way to indicate to SQL Server how many processors to execute a piece of code on. Or rather, it is a way to limit SQL Server from running a statement over all processors on the box. As this post is not about MAXDOP as such, I won’t go into details about it, but if you want to know more
here is an MSDN article covering MAXDOP. Anyway, MAXDOP is set on SQL Server instance level, but can also be used as query hint on individual queries.
Setting MAXDOP for individual statements also work for the statement used in the @input_data_1 parameter on the sp_execute_external_script procedure. So in our code example was can change the @input_data_1 parameter to look like so:
|
|
Code Snippet 5: Using MAXDOP in SELECT
The code in Code Snippet 5 will now restrict the parallelism to use 4 processors, and results coming back will show 4 different process id’s, and - as I mentioned above - during execution there will be 9 RTerm processes created, and when the execution has finished 5 will be in the process pool.
Some Unclear Points
All this seems pretty straight forward, however what is unclear for me is how the interaction between SQL Server and the launchpad service works when executing with parallelism. On the SQL Server side we can see how multiple tasks and workers are invoked when parallelism is in play by executing something like so:
|
|
Code Snippet 6: Viewing Tasks and Workers When Executing
To see this:
- Open a second query window and copy the code from Code Snippet 6 into that window.
- Replace the
<spid_from_script_execute>with the session id (@@SPID) from where you executesp_execute_external_script. - Highlight the Code Snippet 6 code in the query window.
- Execute the
sp_execute_external_scriptcode, where@parallelis set to 1. - Quickly change over to the other query window and execute the code.
The result from the query window where you execute the code from Code Snippet 6 looks something like what you see in Figure 7:
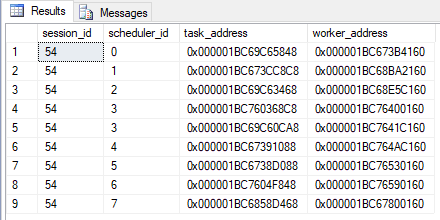
Figure 7: Tasks, Workers and Schedulers*
Ok, we see multiple schedulers, tasks and workers being active when we execute our code, and there is nothing strange in that. Seeing that, I would then have expected that there would be a one-to-one relationship between the tasks and the calls into the launchpad service, but that is not the case.
I verified that by “firing up” my trusted debugger WinDbg and attached it to the launchpad process, similar to what we did in
Internals - II. I then set a breakpoint at launchpad!CLaunchContext::LaunchServTask, and executed the code. My expectation was that I would see how the breakpoint was hit multiple times when I executed with parallelism.
That did not happen, the breakpoint was hit once, and that was it. That leaves me with the question how SQL Server interacts with the launchpad service when executing with parallelism. My guess is that when SQL Server calls into the launchpad service, (which we discussed at length in Internals - I and II), it tells the launchpad service that this call requires parallelism, and the level of it. But as I said, this is just a guess. Maybe someone out there can clarify what goes on.
Summary
In this post I wanted to look at how parallelism affects the creation of RTerm processes in SQL Server R Services. The conclusion is that it does:
- When executing with no parallelism, the launchpad service creates 6 processes by default (can be altered by
PROCESS_POOL_SQLSATELLITE_GROWTH), and the code runs on one, the others are added to the process pool. When the code has finished executing, the executing process is torn down. - When executing under parallelism the launchpad service creates two processes per degree of parallelism. One of the two processes are used to execute on, the other is added to the pool.
- If the level of parallelism is lower than default number of process to be created (or
PROCESS_POOL_SQLSATELLITE_GROWTH) then the launchpad service creates enough processes to satisfy the required level.
- If the level of parallelism is lower than default number of process to be created (or
- Parallelism works with CRAN R functions as well as RevoScaleR.
- The
MAXDOPsetting has impact on the parallelism.
So that’s for now! Thanks once again to Bob for his input and code!! And as I mentioned above, if anyone has input how SQL Server interacts with the launchpad service, when parallelism is in play - I’d be more than happy to hear about it.
If you have comments, questions etc., please comment on this post or ping me.
comments powered by Disqus