In a two-post series, this second post looks at streaming data from a database to Azure Event Hubs using Kafka Connect and Debezium, where Kafka Connect and Debezium run in Docker.
The first post:
-
How to Stream Data to Event Hubs from Databases Using Kafka Connect & Debezium in Docker - I. This post mainly looks at the configuration of Kafka Connect’s
docker-compose.ymlfile to allow us to connect to Event Hubs.
This series came about as I in the post How to Use Kafka Client with Azure Event Hubs, somewhat foolishly said:
An interesting point here is that it is not only your Kafka applications that can publish to Event Hubs but any application that uses Kafka Client 1.0+, like Kafka Connect connectors!
I wrote the above without testing it myself, so when I was called out on it, I started researching (read “Googling”) to see if it was possible. The result of the “Googling” didn’t give a 100% answer, so I decided to try it out, and this series is the result.
In the first post, - as mentioned - we configured Kafka Connect to connect into Event Hubs. In this post, we look at configuring the Debezium connector.
Pre-reqs
The pre-reqs are the same as in How to Stream Data to Event Hubs from Databases Using Kafka Connect & Debezium in Docker - I and if you followed along in that post you should now have:
- A SQL Server database:
DebeziumTest(or whatever you named it). - A table in the database:
dbo.tb_CDCTab1.
In addition to the above, you should also have an Event Hubs namespace. In the namespace you should have created a SAS policy connection string, where the connection string looks like so:
|
|
Code Snippet 1: SAS Policy Connection String
In Code Snippet 1, we see the policy connection string I created in the previous post.
Recap
Before diving into configuring Debezium, let us recap what we did in the
previous post, where we configured the docker-compose.yml file we use for Kafka Connect. In the last post, I divided the file into three parts to look at the details. Here I show the whole file with pointers to interesting areas:
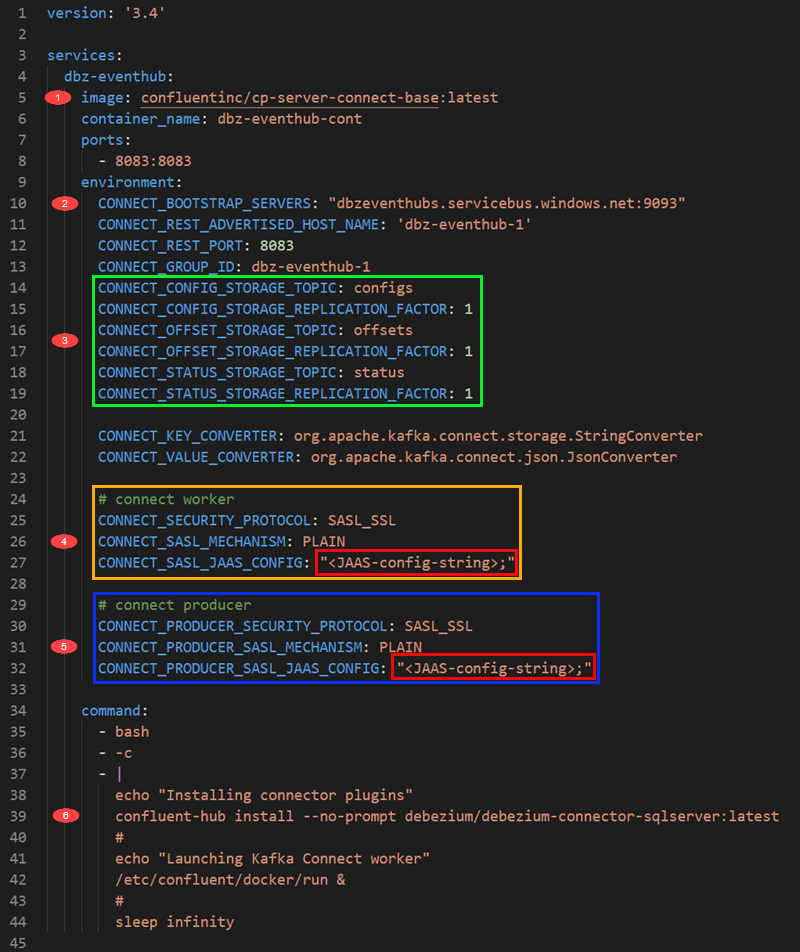
Figure 1: Docker Compose File
The numbered/outlined areas in Figure 1 refer to:
-
The image we use. Here, we use the Kafka Connect base image, which contains the bare minimum for Kafka Connect.
-
Defines the Kafka endpoint for the worker process. This is the Kafka endpoint of the Event Hubs namespace for Event Hubs. You get the endpoint from the SAS policy’s connection string, and you append it with port,
9093, which is the Event Hubs Kafka API endpoint. -
Kafka Connect uses topics to store connectors config, offsets, and statuses. As this is Event Hubs, we see the Event Hub names we want to use (they will be auto-created). We also define the replication factor for the event hubs (topics). In Kafka, the default is 3, but Event Hubs works somewhat differently, so we set the replication factor to 1.
-
This is the security/authentication configuration for the Kafka Connect worker process for connecting to the bootstrap server. Outlined in red, we see how we pass in the JAAS configuration. This is required as Kafka uses JAAS (Java Authentication and Authorization Service) for SASL. The JAAS configuration is based on the Event Hubs namespace configuration string and looks like so:
1 2 3 4 5 6CONNECT_SASL_JAAS_CONFIG: \ "org.apache.kafka.common.security.plain.PlainLoginModule \ required username=\"$$ConnectionString\" \ password=\"Endpoint=sb://dbzeventhubs.servicebus.windows.net/; \ SharedAccessKeyName=KafkaConnect; \ SharedAccessKey=<secret-key>;"\";"Code Snippet 2: JAAS Configuration
Notice in Figure 2 how we set the username to
$$ConnectionStringinstead of the “normal”$ConnectionStringas user name for Event Hubs. Using single$indocker-composeimplies variable substitution, so therefore we “escape” by using$$. -
This is the security/authentication configuration for the connector to connect to the bootstrap server. In this case the bootstrap server is the same for the worker process and the connector, so the JAAS configuration is the same as in Code Snippet 2.
-
We install/deploy Debezium’s SQL Server connector using
confluent-hub install.
Two things to keep in mind in the Kafka Connect configuration are:
- Use
$$ConnectionStringinstead of$ConnectionStringas the user name when connecting to Event Hubs. Read this post to see why we use$ConnectionStringat all when connecting to Event Hubs. - Set the authentication/security for the connector as well, not only the Kafka Connect worker process.
We have now reached more or less where we finished the previous post, let us continue.
Enable CDC
When streaming data using Debezium, CDC (Change Data Capture) must be enabled. So let us enable CDC:
|
|
Code Snippet 3: Enabling Database and Table for CDC
We see in Code Snippet 3 how we:
- Enable CDC on the database.
- After enabling CDC on the database, we enable it for the table(s) from which we want to capture changes.
Please remember that the SQL Server Agent needs to be started before enabling CDC. Having enabled CDC, we can now look at the connector.
Debezium Connector
Above, in Figure 1, we see how we install/deploy the SQL Server connector, and in the last post, we saw how the connector was loaded in the Kafka Connect worker process after we did docker-compose up -d.
The connector is loaded, but it is not doing anything. To enable the connector, we configure it using a JSON file, which we then POST to a Kafka Connect endpoint. To POST the file, you can use your favorite tool, Postman, curl, etc. I tend to like Postman, so that is what I use later on.
Before we go any further, even though this post looks in somewhat detail at configuring Debezium, it looks at it from the perspective of configuring it to be able to communicate with Event Hubs. So, if you want/need more information about Debezium configuration in general, look here.
Debezium Event Hubs (Topics)
During the configuration of the Debezium connector, two Debezium specific event hubs are created, regardless of the tables we are interested in:
- Event hub for schema changes. The connector writes schema change events to this event hub whenever a schema change happens for a captured table. The name of the event hub is the name in the
database.server.nameconfiguration property in the configuration file. - Event hub for database history. Schema changes are written to the schema change event hub, and also to this database history event hub. You set the name of this event hub in the
database.history.kafka.topicconfiguration property in the configuration file.
Let us look at database history configuration.
Database History
The database history requires some specific configuration. This caused me issues when I tried Debezium to Event Hubs, so I thought I better cover the database history configuration in a bit more detail.
NOTE: The database history properties are not SQL Server specific, but every Debezium connector requires them, except for the connectors for PostgreSQL, Cassandra, and Vitess.
So, I mentioned above about the database history event hub and how the connector writes schema changes to that event hub. We define the event hub name in the database.history.kafka.topic configuration property. We also need to specify the endpoint where the event hub should be created/exists. We do that via the database.history.kafka.bootstrap.servers property. Keep in mind that the database history endpoint should be the same as the Kafka Connect process endpoint. That’s what all documentation says anyway, and I have not tried anything differently.
NOTE: The timeout for creating the database history topic is very short, so when you connect to the cloud, whether it is Confluent Cloud or Azure Event Hubs, you should create the event hub (topic) manually. I.e. creating it before
POST:ing the connector configuration. Oh, and when you create it, you have to create it with a partition count of 1.
Taking the above into consideration, the database history configuration looks something like so:
|
|
Code Snippet 4: Database History Configuration
In Code Snippet 4, we see the database history configuration properties, and we see that database.history.kafka.bootstrap.servers has the same value as in Figure 1, point two. The event hub name is set to dbzdbhistory. As mentioned before, we should manually create that event hub to avoid timeout errors.
This looks good! But wait, there is more - and this was one of the things I completely missed when I initially tested Debezium with Event Hubs. What I missed was that if your Kafka cluster/Event Hubs is secured, you must add the security properties prefixed with database.history.consumer.* and database.history.producer.* to the connector configuration:
|
|
Code Snippet 5: Database History Security Configuration
In Code Snippet 5, we see how the database history security is set up like the security in Figure 1. One difference is that we set it up for both consumer and producer, as the connector will both write to and read from the topic. The JAAS configuration string looks like what we see in Code Snippet 2; apart from that the user name is $ConnectionString. I.e. one dollar sign.
Configuration File
Having covered some of the essential parts of the connector configuration, let us look at what the complete configuration file looks like:
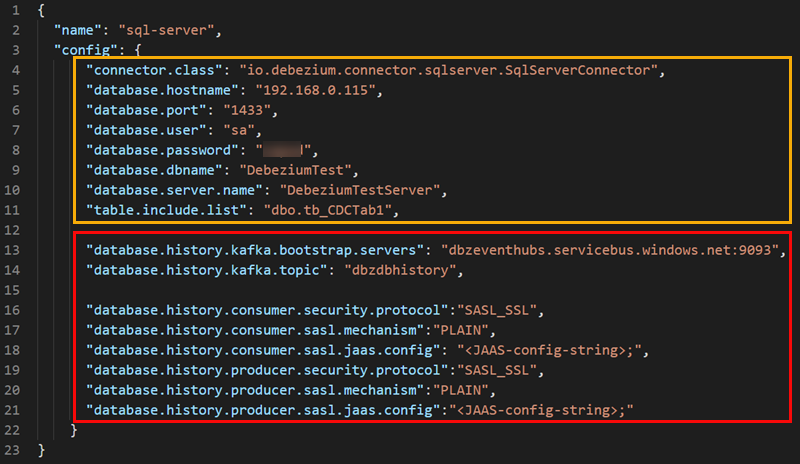
Figure 2: Debezium Configuration File
Outlined in yellow in Figure 2 are the configuration properties mostly related to the source database. Some properties to look at are:
connector.class: this defines what Debezium connector to use.database.dbname: the database from which we capture events.database.server.name: logical name that identifies the SQL Server instance (it can be an arbitrary string). An event hub with this name will be created to capture schema changes (as mentioned above). This name is also used as a prefix for all event hub names created by the connector for tables from which we capture changes.table.include.list: a comma-separated list of fully-qualified table names for tables from which we capture changes.
The outlined in-red portion in Figure 2 is required for database.history.*. Since I covered quite a lot about database history above, I will not go further into it.
Configure the Connector
We are now ready to “spin up” Kafka Connect, followed by configuring and enabling the connector.
NOTE: When I am testing things out, I ALWAYS tear down my environment before each run. I.e., delete the connector if it is created, take down Docker, and delete all relevant topics.
Let’s do this! We start with “spinning up” Kafka Connect like we did in the
last post: docker-compose up -d. We wait a minute or two, and then we do the same checks as in the
previous post:
- In the Azure portal, ensure that the Kafka Connect internal topics have been created. In my case,
offsets,status, andconfigs. - Look and see that the connector is loaded:
GET http://127.0.0.1:8083/connector-plugins.
I don’t know about you, but in my environment, it looks good. We are now ready to configure the connector. Before we do that, ensure that the database and table are CDC enabled and that you have manually created the database history event hub.
Now let’s do it. Let us POST the configuration:
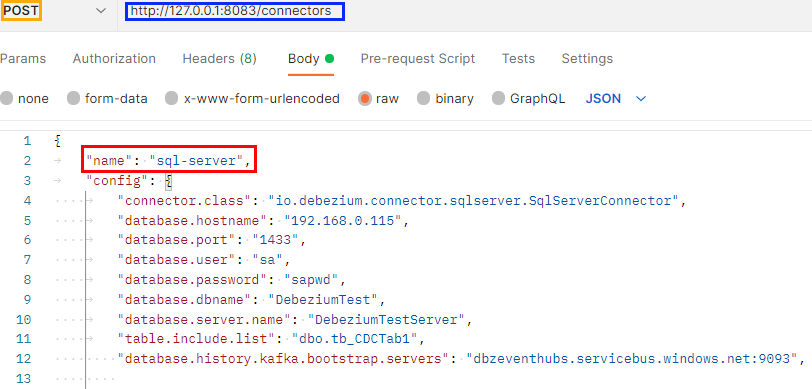
Figure 3: POST Configuration
In Figure 3, we see our POST call (outlined in yellow) to the connectors endpoint (outlined in blue), and we also see part of the configuration file. When configuring a connector, we give it a name, and in my case, I named it sql-server (imaginative - I know). After we have POST:ed we see if it worked:
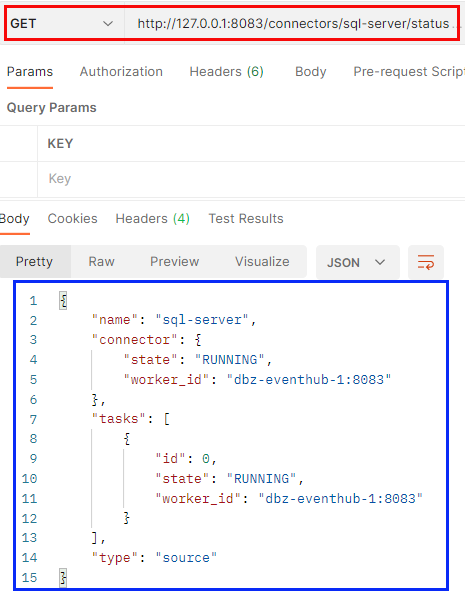
Figure 4: Connector Status
We see in Figure 4 how we do a GET call against the status endpoint with the connector’s name as part of the path. According to what is outlined in blue, all looks OK.
NOTE: When checking the status of a newly created connector, it is a good practice to wait a little while (10 - 20) seconds right after creation before checking the status. This is to give the connector some time to “spin up”. Alternatively, run the status check a couple of times.
The other thing we can do to ensure all is OK is to look in the portal and see what event hubs we have:
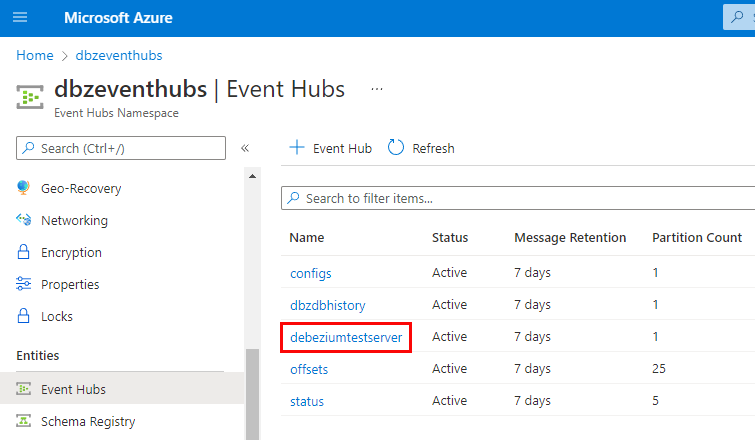
Figure 5: Created Event Hubs
At first glance at Figure 5 all looks OK. We see the connector’s event hub for scheme changes (debeziumtestserver). So far, so good. But what about the event hub for the table we want to capture changes from: dbo.tb_CDCTab1? Where is that event hub? The answer to that is that the event hubs for capture table events are not created until an event happens:
|
|
Code Snippet 6: Ingest Data
After executing the code in Code Snippet 6, you refresh the event hubs in the portal, and you see this:
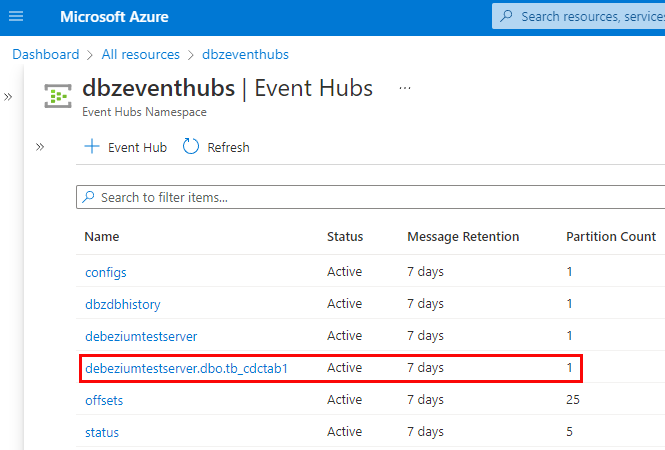
Figure 6: Event Hub for Table
After doing an insert in the table, we see in Figure 6 an event hub created for that table. We assume that events have been published to the event hub. To further “prove” that, we look at that particular event hub’s overview page in the portal and its stats:
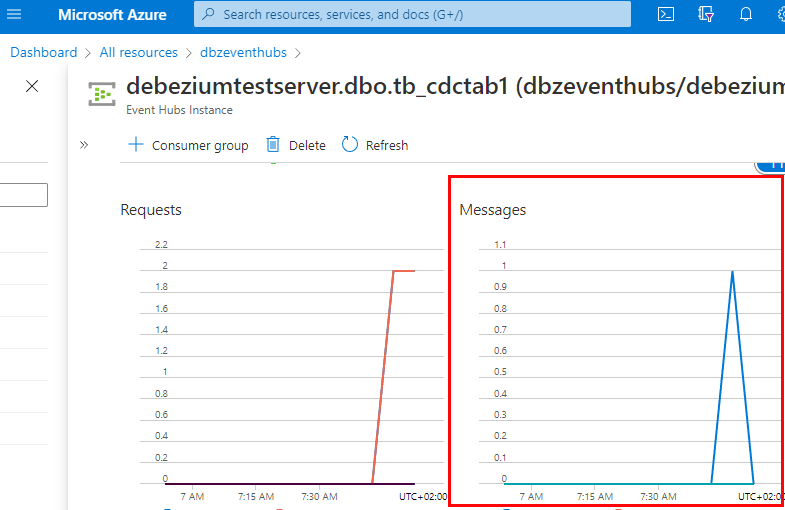
Figure 7: Event Hub Stats
The stats for incoming messages are outlined in red in Figure 7, and we see how one message has arrived. It works - yay!
Summary
In the previous post and this, we set out to see if we can use Debezium and Kafka Connect to stream data from databases to Event Hubs. We have now seen it is possible!
Things to keep in mind:
- When connecting to Event Hubs, we use the connection string from a SAS policy.
- We use JAAS configuration to set the user name and password. For Event Hubs the username is the literal string
$ConnectionString, and the password is the SAS policy’s connection string. - If we use
docker-compose, we set the user name in the JAAS configuration to$$ConnectionStringto avoid variable substitution. - When configuring the security for Kafka Connect, you do it both for the Kafka Connect worker process and the connector.
- Almost all Debezium connectors require a database history event hub (topic).
- Since the timeout for automatic creation of the event hub is very short, the event hub should be created manually before configuring the connector.
- We need to set security for the database history endpoint and do it for both consumer and producer (
database.history.consumer.*,database.history.producer.*).
Lastly, I would not have been able to get this to work if it hadn’t been for the blog post:
- Using Kafka Connect and Debezium with Confluent Cloud. This post by by Kafka guru Robin Moffat gave me the necessary pointers for the connector configuration - especially the security configuration for the database history event hub.
As I said, Robin Moffat is a Kafka Guru, and if you are into Kafka, then you MUST read his blog.
~ Finally
If you have comments, questions etc., please comment on this post or [ping][ma] me.