As you may know, a while back I wrote some posts about the support for Java in SQL Server 2019: SQL Server 2019 Extensibility Framework & Java. The posts covered in some detail how Java in SQL Server worked, and how to write Java code for use in SQL Server. However, a week or two ago “the sky came tumbling down” when Microsoft released SQL Server 2019 CTP 2.5.
NOTE: CTP stands for Community Technology Preview and is like a beta release.
What Microsoft did in CTP 2.5 was to introduce Java Language Extension SDK, and your Java code now needs to inherit an abstract base class from the SDK. This requirement makes a large part of my previous posts “null and void”, so in this post, we look at what to do going forward.
What happened here, (functionality introduced that negates previous functionality), is the danger when writing about beta releases. I should know, as it has happened before. Back in 2003 some colleagues and I wrote a book about the upcoming SQL Server 2005 release: A First Look at SQL Server 2005 for Developers, and we wrote the book based on beta releases. When Microsoft eventually released SQL Server 2005, at least a couple of chapters in the book covered functionality that no longer existed. Well, what can you do?
Anyway, let us go back to SQL Server 2019 and Java.
Recap (pre CTP 2.5)
When I started this post, my idea was to do a brief recap of what the Java implementation looked like in the previous CTP’s, to show what it used to be, and refer to that in this post. After I had written 90% of the Recap I realized it had become way too long, so I decided to skip it.
If you are interested in what it used to be, you can go back and read the posts in the SQL Server 2019 Extensibility Framework & Java series. The most relevant posts are:
- SQL Server 2019 Extensibility Framework & Java - Hello World: We looked at installing and enabling the Java extension, as well as some very basic Java code.
- SQL Server 2019 Extensibility Framework & Java - Passing Data: In this post, we discussed what is required to pass data back and forth between SQL Server and Java.
-
SQL Server 2019 Extensibility Framework & Java - Null Values: This, the
Null Values, post is a follow up to the
Passing Data post, and we look at how to handle
nullvalues in data passed to Java.
Demo Data
In this post, we use some data from the database, so let us set up the necessary database, tables, and load data into the tables:
|
|
Code Snippet 1: Create Database Objects
We see from Code Snippet 1 how we:
- Create a database:
JavaTestDB. - Create a table:
dbo.tb_Rand10. - Insert some data into the table.
The data we insert is entirely random, but it gives us something to “play around” with. Now, when we have a database and some data let us get started.
Microsoft Extensibility SDK for Java
As mentioned above, in CTP 2.5, Microsoft changes the way we implement Java code in SQL Server, and they do it to create a better developer experience when writing Java code for SQL Server.
NOTE: I am not totally sure this change gives us a better developer experience, I guess time will tell.
In CTP 2.5 and onwards when you write Java code for SQL Server you implement your code using the Microsoft Extensibility SDK for Java, (SDK). The SDK acts sort of like an interface as it exposes abstract classes that your code need to extend/target, (more about that later).
The SDK comes in the form of a .jar file, and you download the SDK from
here. Since a .jar file is essentially an archive file you can open the SDK .jar with your favorite file archiver utility and when you do, you see:

Figure 1: SDK Jar - I
We see in Figure 1 how I have extracted the SDK .jar to a folder, and how the .jar file contains at the top level two folders: com and META-INF. The com folder is the top level folder for the Java SDK package, and below we look a bit more into it. The META-INF folder contains metadata information about the .jar package, and in this post we do not care about it.
Coming back to the com folder I mentioned it was the top level folder for the package, and if we drill down into it, it looks something like so:
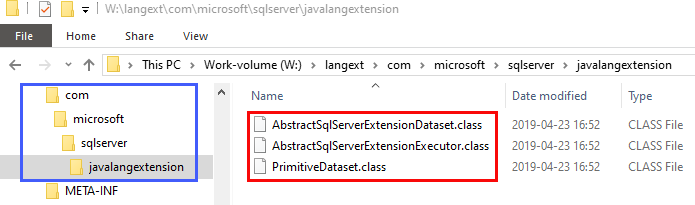
Figure 2: SDK Jar - II
In Figure 2, outlined in blue, we see how the package name follows the standard of a hierarchical naming pattern: com.microsoft.sqlserver.javalengextension. Below javalangextension we have three classes outlined in red - these are the classes mentioned above:
AbstractSqlServerExtensionExecutorAbstractSqlServerExtensionDatasetPrimitiveDataset
Let us look at what these classes do.
AbstractSqlServerExtensionExecutor
The AbstractSqlServerExtensionExecutor abstract class is the class you need to inherit from/extend in the classes that SQL Server calls. The source code looks like so (I have copied the code from
here):
|
|
Code Snippet 2: AbstractSqlServerExtensionExecutor
When looking at the code in Code Snippet 2 we see how the class:
- Has three class members that according to the comments have something to do with application specifics.
- Has three methods:
init,execute, andcleanup.
Later in the post, I come back to the class members, but now I want to look at the three methods. More specifically, I want to look at the execute method since init, and cleanup are fairly self-explanatory: init if any initialization needs to be done, and cleanup for any, well, clean up after usage.
execute
That leaves us execute. Notice in Code Snippet 2 how both init and cleanup are no-ops, whereas execute is not. Furthermore, if someone calls execute in a class which extends AbstractSqlServerExtensionExecutor, and there is no implementation of execute the method throws an UnsupportedOperationException error. So who would call execute?
To answer the question about who is calling execute, let us remind ourselves what happens when we call sp_execute_external_script. We do that by looking at what happens when we execute R/Python code. In my
SQL Server R Services series we talked about the components which make up SQL Server Machine Learning Services, and we saw how the flow when we execute an external script, looks something like so:
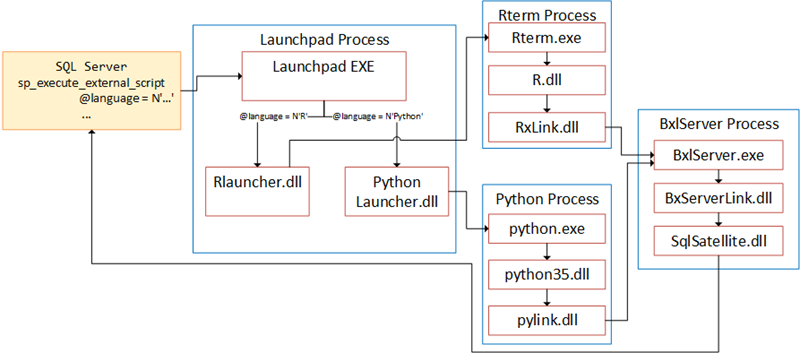
Figure 1: Components & Flow
The flow is similar when we execute Java code; e.g. when we execute sp_execute_external_script SQL Server calls into the Launchpad service which then “spins” up the external engine and your code runs. In this case the call goes into the Java extension library (a .dll), and the extension library calls into the JVM. So it is the extension library that calls the execute method. This is different to pre CTP 2.5 where the extension called a method specified in the @script parameter: @script = N'packagename.classname.method', and now it is: @script = N'packagename.classname'.
The implication of this is that in pre CTP 2.5 you could have multiple “entry” points, (methods), to call into, whereas now the entry point is the execute method.
Above I mentioned that one of the reasons for introducing the SDK was to create a better developer experience, and the signature of execute gives some hints about this:
|
|
Code Snippet 3: Execute Method
From the signature in Code Snippet 3 we see how the execute method takes two parameters and has a return type. This in itself is interesting as pre CTP 2.5 the methods you called into did not allow parameters, and had to be void.
When we look at the parameters, the execute method expects we see they are:
AbstractSqlServerExtensionDataset inputLinkedHashMap<String, Object> params
The input parameter references any dataset you pass in the class, (from the @input_data_1 parameter in sp_execute_external_script). We talk more about AbstractSqlServerExtensionDataset below.
What about the params parameter? As the name implies, it has to do with passing in parameters to the execute method. Remember that in pre CTP 2.5 a method could not have parameters and if you wanted to send in parameters you first defined them in the @params parameter in sp_execute_external_script and declared them like so:
|
|
Code Snippet 4 Call from T-SQL to Java with Parameters
What we see in Code Snippet 4 how we add two parameter definitions, (@x and @y), to the @params parameter, and how we then declare and assign values to them: @x = @p1, and @y = @p2. In the Java code, as the methods had to be parameterless, we added the parameters as class members and named them the same as in the SQL code, but without the @ sign. In the methods, we then used those class members.
In CTP 2.5 and onwards, we still declare the parameters as before in sp_execute_external_script, but we no longer need to define the parameters as class members in the Java code. The Java extension dll takes the parameters and populates the LinkedHasMap, with the parameters defined in sp_execute_external_script. The extension adds them as key-value pairs, with the key being the parameter name, (without the @), and the value is the value of the parameter. In the execute method, you retrieve them from the params parameter and use them.
So far I have not mentioned anything about the return type of the execute method, other than it being an AbstractSqlServerExtensionDataset, (as is the first input parameter in execute). So, let us discuss AbstractSqlServerExtensionDataset.
AbstractSqlServerExtensionDataset
As the name implies, the AbstractSqlServerExtensionDataset “deals” with datasets. In pre CTP 2.5 if you wanted to send in a dataset like: SELECT col1, col2 FROM someTable, you had to - in your class - define arrays as class members representing the columns in the dataset. For return datasets, you had to do the same. Both for input datasets as well as return datasets the class members had to have well-known names: inputDataCol*N*, and outputDataCol*N*, where N is the column number (1 based). For input datasets, the Java extension populated the inputDataCol class members, and in your code, you looped through them. When returning a dataset from your code, you populated the outputDataCol class members, and the Java extension converted it to a result set when returning.
Many developers found the above complex and convoluted, so the Java SDK introduces the AbstractSqlServerExtensionDataset. The class contains methods for handling input and output data, and you see the source code for it
here. As a developer, you - instead of defining all the various input and output column arrays - create an implementation of the AbstractSqlServerExtensionDataset and uses that in the code. Unless you have specific requirements, you do not even have to create the implementation of AbstractSqlServerExtensionDataset; an implementation already exists in the SDK, the PrimitiveDataset.
PrimitiveDataSet
The PrimitiveDataset is a concrete implementation of the AbstractSqlServerExtensionDataset, and it is similar to how we handled datasets pre CTP 2.5 in that it stores simple types as primitives arrays. You find the source of the class
here, and below, we see how we use it.
Java Code
It is time for some code, but before we do that, ensure you have downloaded the SDK from here. For the code I write here I use VS Code together with the Maven extension. I wrote a blog post about VS Code, Java and Maven here if you want to refresh your memory.
I start with creating a Maven project based on the Maven archetype maven-archetype-quickstart. This gives me a “starter” class App containing a public static void main() entry point. I add to the project a class JavatTest1 in the source file JavaTest1.java, and this is the class that I want to inherit from AbstractSqlServerExtensionExecutor. So I write some code like so:
|
|
Code Snippet 5: Extending AbstractSqlServerExtensionExecutor
As we see in Code Snippet 5 I extend the AbstractSqlServerExtensionExecutor class, but when I do it I immediately see red “squiggles” under AbstractSqlServerExtensionExecutor, and when I mouse over I get a dialog like so:

Figure 2: Inheritance Error
Maven Dependencies
As we see in Figure 2, it looks like Maven/VS Code cannot resolve the name AbstractSqlServerExtensionExecutor. That is not that strange as we do not have any dependency on the .jar file. So how do we set a dependency on the downloaded SDK? Well, we add a dependency in the pom.xml file, and, (for Maven), it needs to be in the form of:
|
|
Code Snippet 6: Dependency
We see in Code Snippet 6 how a dependency consists of a groupId, artifactId, and version. Usually, you follow the Maven
naming standards, but in our case, where we have downloaded the SDK jar directly, we do not have to do that. Regardless of that, the artifactId needs to match the filename, sans extension, and a version number is required.
The dependency points out where to find the dependent file in the local Maven repository, or to be downloaded to from a remote repository. On Windows, we find the local Maven repository at %USERPROFILE%\.m2\repository. Coming back to Code Snippet 6, the groupId\artifactId\version defines the folder hierarchy in the local Maven repository:
|
|
Code Snippet 7: Java SDK Dependency
The dependency in Code Snippet 7 sets the expectation that the .jar file is located at: %USERPROFILE%\.m2\repository\nielsb\mssql-java-lang-extension\1.0. The nielsb directory is just a random directory, and it could be anything. The one thing to think about is that when you copy the actual file to the directory, the file-name needs to include the version. So as per Code Snippet 7, the file name is: mssql-java-lang-extension-1.0.jar:
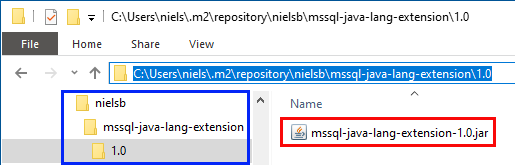
Figure 3: Folder Hierarchy Dependency
In Figure 3 we see the “layout” of the local Maven repository after I have set it up for the SDK dependency. Outlined in blue we see the different folders below..\m2\repository, and the outline in red shows the renamed SDK file. Having done this VS Code now “picks up” the dependency and we can start using it in our code.
Use the SDK
Our project should now compile OK, so let us add some logic to the JavaTest1 class. We start with writing similar code to what we saw in the [SQL Server 2019 Extensibility Framework & Java - Hello World] post; the adder method where we took two variables and added them together.
However, now when we use the SDK, we do not have to declare the variables as global class members, they are instead part of the params parameter in the execute method:
|
|
Code Snippet 8: JavaTest1 Class and Execute Method
In Code Snippet 8 we see the complete JavaTest1 source code. We see how we do some import of classes we use, and in the execute method, we get the two parameters we want from the params parameter. We return null since we do not have any resultset to pass back. Oh, the Java language extension does, still, not support output parameters.
In the VS Code project we have an App.java source file with a main method, by which we can test that our code works:
|
|
Code Snippet 9: Main Method
In Code Snippet 9 we see a big difference between pre CTP 2.5 and now, in that now the method (execute) is not required to be static any more. The Java language extension now “news up” an instance of the class that we call into.
Let us create a .jar file out of our project so we can deploy to SQL Server. Since I am using Maven, in the VS Code’s’ Maven extension I click on package, (read more about it in the
Java with Visual Studio Code post). What happens is that Maven recompiles, (if any changes have taken place), and then builds the .jar file, and places it in the ..\target directory.
Theoretically when we have the .jar file we can deploy it to the database where we want to execute the code from, by using the CREATE EXTERNAL LIBRARY statement we discussed in the SQL Server 2019, Java & External Libraries -
I, and
II posts. The issue with that is if we try to do that in a database where we have not deployed any Java code to, exceptions happen when we execute against the code, as the SDK is not present in the database (the .jar does not contain the SDK). So we first need to deploy the SDK, and as we do it on the local machine, we can deploy it based on file location:
|
|
Code Snippet 10: Create SDK External Library
When you have run the code in Code Snippet 10 you can check that everything worked by executing: SELECT * FROM sys.external_libraries, and you see an entry named javaSDK. Oh, the name we give the library is of no importance. Having done this, we deploy our .jar to the database, also using CREATE EXTERNAL LIBRARY:
|
|
Code Snippet 11: Create External Library from Java Project
After executing the code in Code Snippet 11 we try and execute the Java code:
|
|
Code Snippet 12 Call from T-SQL to Java with Parameters
The code in Code Snippet 12 is almost identical to what we see in Code Snippet 4, apart from that we no longer call into a method, (adder), but instead a class: JavaTest1. Unfortunately, when we run the code in Code Snippet 12 we get an exception:
|
|
Code Snippet 13: Exception
The exception is, as we see in Code Snippet 13: Unsupported executor version encountered, hmm what is that? Go back and look at Code Snippet 2, and the beginning of the AbstractSqlServerExtensionExecutor class:
|
|
Code Snippet 14: AbstractSqlServerExtensionExecutor
Notice in Code Snippet 14 the four members:
public final int SQLSERVER_JAVA_LANG_EXTENSION_V1 = 1;protected int executorExtensionVersion;protected String executorInputDatasetClassName;protected String executorOutputDatasetClassName;
The four members above are there for the Java language extension to use. They indicate what version of the extension it is and what class to use for input and output dataset. These are required, and we set them like so:
|
|
Code Snippet 15: Executor Version and Data Set Class Names
As we see in Code Snippet 15 we set the members in the class ctor, and when we have done it we:
- Re-build the
.jar. - Drop the external library.
- Re-create the external library as in Code Snippet 11.
When we now execute the code in Code Snippet 12:
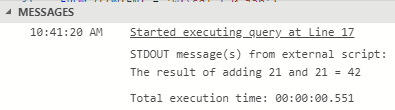
Figure 4: Success
So, after we have set the various member values, all works OK. It is worth noticing that even though we do not pass any datasets, we still need to set the values for executorInputDatasetClassName and executorOutputDatasetClassName. Having said that, let us look at how we use datasets.
To look at datasets we want to pass in data from the table dbo.tb_Rand10, in fact, we want to pass in the RowID, x, and y columns: SELECT * FROM dbo.tb_Rand10. In our Java code, we then add the value of the x, and y columns together and return a dataset containing the RowID and the result. So we create a new class, (and source file), JavaTest2. In the execute method, we do as follows:
|
|
Code Snippet 16: Input and Output Datasets
In the execute method in Code Snippet 16 we see how we expect the Java language extension to pass in an instance of a PrimitiveDataset as the input parameter. In our code, we then:
- Take the individual columns and convert them to arrays.
- Create two output arrays, one for the
RowID, and one for the result.
When we have the output arrays, we loop the input arrays, and:
- Assign the
RowIDto the array forRowID. - Get the values for the
xandycolumn arrays. - Add them together and assign the value to the output result array, (
outRes).
We then create an instance of the PrimitiveDataset class, and:
- Add column meta data for the columns we want to return.
- Assign the output arrays to the output columns.
- Finally we return the
PrimitiveDatasetinstance.
We can now compile the code and create a .jar file, and deploy to the database as we did after Code Snippet 15. The code to call into the class looks like so:
|
|
Code Snippet 17: SQL Code to Pass in Data
In Code Snippet 17 we pass in data via the @input_data_1 parameter, and we use the WITH RESULT SETS to format the output. The result when we execute looks like so:
Figure 5: Data Passing
We see in Figure 5 that our code is working, and we get back the result of adding the x, and y columns. Happy Days!
Summary
In this post, we set out to look at how the introduction of the Java Language Extension SDK changes the programming model when writing Java code that should be called from SQL Server. However, before we started to look into the programming model, we looked at how we can add dependencies to VS Code and the Maven extension. We saw that:
- We add a
<dependency>to the<dependencies>section. - The
<dependency>consists (at least) ofgroupId,artifactId, andversion. - The
groupId,artifactId, andversionshould match the directory structure of the local Maven repository. artifactIdcorresponds to the dependency file, sans extension.- The name of the dependency file we copy to the local repository must include the
<version>number.
So what about the SDK programming model? We saw that:
- Our classes which we want to call into need to inherit from
AbstractSqlServerExtensionExecutor. - We have to implement an “entry-point” method:
execute, which is what the Java language extension calls. - We no longer need to create class member variables for parameters, as the
executemethod accepts aLinkedHashMapcorresponding to the parameters we want to pass in. - We no longer need to create class member variables for input dataset , as the
executemethod accepts a concrete implementation ofAbstractSqlServerExtensionDataset. - The SDK contains a concrete implementation of
AbstractSqlServerExtensionDataset:PrimitiveDataset. - For return datasets we use a concrete implementation of
AbstractSqlServerExtensionDataset, for examplePrimitiveDataset. - The class we call into needs to expose certain members indicating version of the language extension and class name of the
AbstractSqlServerExtensionDatasetimplementation.
This post was a high level overview of the new programming model using the SDK, and I have only “scraped the surface” on certain parts of it. Expect follow-up posts going deeper into the programming model, for example how to handle null values within the AbstractSqlServerExtensionDataset.
STOP THE PRESSES
While I wrote this blog post Microsoft released SQL Server CTP 3.0, which introduces further changes to the Extension Language programming model. Instead of delaying this post, I cover that in future posts.
~ Finally
If you have comments, questions etc., please comment on this post or ping me.
comments powered by Disqus